
As AI models continue to scale, networking has become just as important as GPU performance. Modern AI workloads rely on distributed GPU clusters that generate massive east-west traffic during training and inference, making low-latency, high-bandwidth networking essential for overall system efficiency.
This is where AI Cluster Networking plays a critical role.
AI cluster networking refers to the high-performance network infrastructure that connects GPU servers, storage systems, and AI accelerators inside AI data centers and HPC environments. Unlike traditional enterprise networks, AI clusters require ultra-fast communication between nodes to support distributed computing frameworks such as NCCL and RDMA-based GPU communication.
To reduce bottlenecks and maximize GPU utilization, modern AI fabrics commonly use technologies such as:
-
InfiniBand
-
RoCEv2 and RDMA
-
Lossless Ethernet fabrics
-
Spine-leaf network architectures
-
400G and 800G optical interconnects
At the physical layer, optical modules have become a key part of AI infrastructure design. High-speed transceivers such as QSFP-DD and OSFP modules enable scalable 400G and 800G connectivity between switches and GPU servers while maintaining low latency and high port density.
In this guide, we will explain how AI cluster networking works, compare InfiniBand and RoCEv2 architectures, examine RDMA and congestion control technologies, and explore how optical modules support modern AI cluster scalability in 2025 and beyond.
⭐ What Is AI Cluster Networking?
AI cluster networking refers to the high-performance network fabric used to connect GPU servers, AI accelerators, storage systems, and switches inside AI data centers and high-performance computing (HPC) environments. Its primary purpose is to enable extremely fast data exchange between compute nodes during distributed AI workloads.
In practical engineering terms, AI cluster networking is designed to solve one critical problem: keeping GPUs fully utilized during large-scale training and inference tasks. Since modern AI models are too large to run efficiently on a single GPU or even a single server, workloads are distributed across multiple nodes that must constantly synchronize data with each other. The network therefore becomes part of the compute system itself rather than just a transport layer.
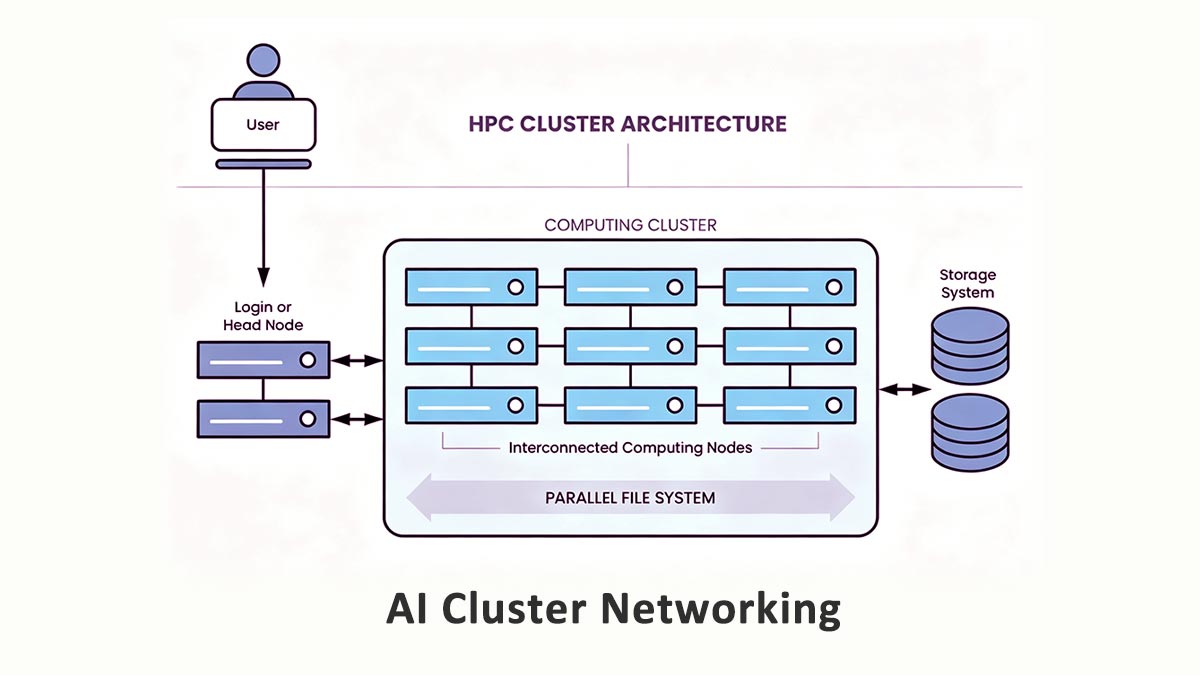
Unlike conventional enterprise networks that mainly handle user-to-server communication, AI clusters generate massive amounts of east-west traffic — data moving laterally between GPUs, servers, and storage systems inside the data center.
Why East-West Traffic Dominates AI Training
Distributed AI training requires GPUs to exchange gradients, tensors, model parameters, and synchronization data continuously. During operations such as data parallelism, tensor parallelism, and pipeline parallelism, every GPU may communicate with many other GPUs simultaneously.
This creates extremely bandwidth-intensive east-west traffic patterns.
For example, during large language model (LLM) training, GPUs frequently perform collective communication operations such as:
-
All-Reduce
-
All-Gather
-
Broadcast
-
Reduce-Scatter
These operations generate heavy inter-node traffic that is highly sensitive to:
-
Latency
-
Packet loss
-
Congestion
-
Jitter
-
Network oversubscription
Even small delays in synchronization can leave expensive GPUs waiting idle, significantly reducing cluster efficiency and increasing training time.
Because of this, AI networking environments commonly deploy:
-
Non-blocking spine-leaf topologies
-
RDMA-enabled fabrics
-
Lossless Ethernet or InfiniBand
-
400G and 800G optical interconnects
-
Intelligent congestion control mechanisms
The goal is to minimize communication overhead and maintain predictable low-latency performance across the cluster.
Training vs. Inference Networking Requirements
Although both AI training and AI inference rely on high-speed networking, their traffic patterns and infrastructure requirements are very different.
1. AI Training Networks
AI training environments prioritize:
-
Ultra-low latency
-
High throughput
-
GPU synchronization efficiency
-
Large east-west bandwidth capacity
-
RDMA and collective communication optimization
Training clusters often use InfiniBand or RoCEv2 fabrics with 400G/800G optical modules to support continuous GPU-to-GPU communication at scale.
2. AI Inference Networks
Inference workloads are usually more focused on:
Inference clusters may not require the same level of ultra-low-latency synchronization as training environments, especially for single-node or lightly distributed inference workloads. In many cases, high-speed Ethernet fabrics are sufficient.
However, as large-scale distributed inference and real-time generative AI applications continue to grow, inference networking requirements are also becoming more demanding, especially for multi-node AI serving architectures.
⭐ AI Cluster Networking Architectures: InfiniBand, RoCEv2, and Ethernet
Selecting the right AI cluster networking architecture directly impacts GPU utilization, latency, scalability, and deployment cost. Today, most AI infrastructures are built around three main approaches: InfiniBand, RoCEv2, and standard Ethernet.
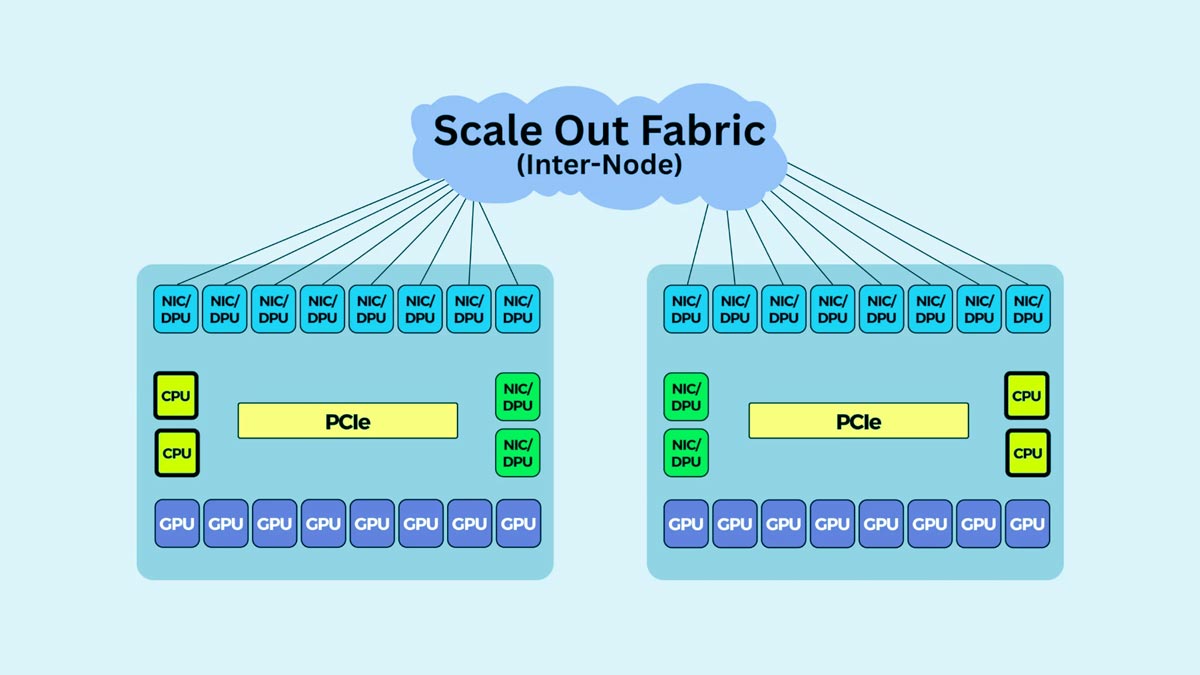
InfiniBand
InfiniBand is widely used in hyperscale AI training and HPC environments because it delivers ultra-low latency, high throughput, and advanced congestion control. It is optimized for RDMA and large-scale GPU communication, making it ideal for distributed AI training workloads.
Key advantages include:
However, InfiniBand also has higher costs and greater deployment complexity, making it most suitable for:
RoCEv2
RoCEv2 (RDMA over Converged Ethernet) brings RDMA capabilities to Ethernet networks. It offers a strong balance between performance, scalability, and cost while integrating more easily with enterprise infrastructure.
Benefits of RoCEv2 include:
-
Lower cost than InfiniBand
-
High-speed Ethernet compatibility
-
Good scalability for AI workloads
-
Easier enterprise integration
To achieve stable performance, RoCEv2 requires proper configuration of lossless Ethernet technologies such as PFC and ECN.
RoCEv2 is commonly used in:
Standard Ethernet
Standard Ethernet remains a practical option for smaller AI deployments and inference clusters where ultra-low-latency GPU synchronization is less critical.
Advantages include:
-
Lower deployment cost
-
Simplified management
-
Broad compatibility
-
Flexible scaling
Modern 100G and 400G Ethernet fabrics can support many AI inference workloads effectively, although they may not match RDMA-based fabrics for large-scale distributed training.
InfiniBand vs. RoCEv2 vs. Ethernet
|
Feature
|
InfiniBand
|
RoCEv2
|
Ethernet
|
|
Latency
|
Lowest
|
Very low
|
Moderate
|
|
RDMA Support
|
Native
|
Supported
|
Limited
|
|
Cost
|
Highest
|
Medium
|
Lowest
|
|
Complexity
|
High
|
Medium
|
Low
|
|
Best Use Case
|
Large AI training
|
Enterprise AI clusters
|
Inference & smaller deployments
|
In general, InfiniBand remains the top choice for maximum AI training performance, RoCEv2 provides the best balance of cost and scalability, and standard Ethernet is often sufficient for inference-focused AI environments.
⭐ How to Design a Low-Latency AI Fabric
Designing a low-latency AI fabric is critical for maintaining high GPU utilization and efficient distributed training. In modern AI clusters, the network must support massive east-west traffic with minimal congestion, packet loss, and synchronization delay.
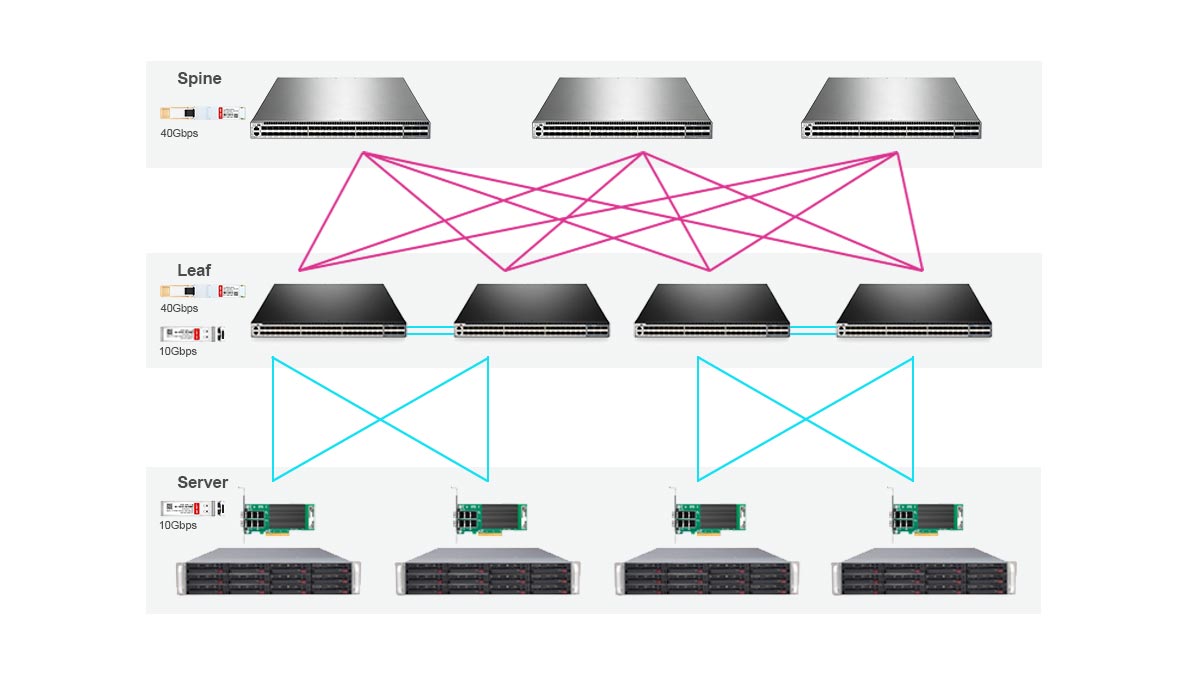
Spine-Leaf and Non-Blocking Architecture
Most AI clusters use a spine-leaf topology because it provides predictable low-latency communication and scalable bandwidth across GPU nodes.
In this architecture:
-
Leaf switches connect directly to GPU servers
-
Spine switches interconnect all leaf switches
-
Every leaf switch has equal-cost paths to other leaves
This design minimizes bottlenecks and supports high-bandwidth east-west traffic patterns common in AI training.
Large AI deployments often aim for a non-blocking fabric, where the network provides enough bandwidth to avoid contention between nodes during GPU communication operations such as All-Reduce and All-Gather.
Oversubscription Strategy
Oversubscription occurs when available uplink bandwidth is lower than total server-facing bandwidth.
For AI training clusters, low oversubscription is important because distributed GPU workloads generate continuous inter-node traffic. High oversubscription can increase latency and reduce training efficiency.
Common approaches include:
-
1:1 non-blocking designs for large AI training clusters
-
Low oversubscription ratios for medium GPU deployments
-
Higher oversubscription for inference-focused environments
The ideal ratio depends on workload type, GPU count, and budget constraints.
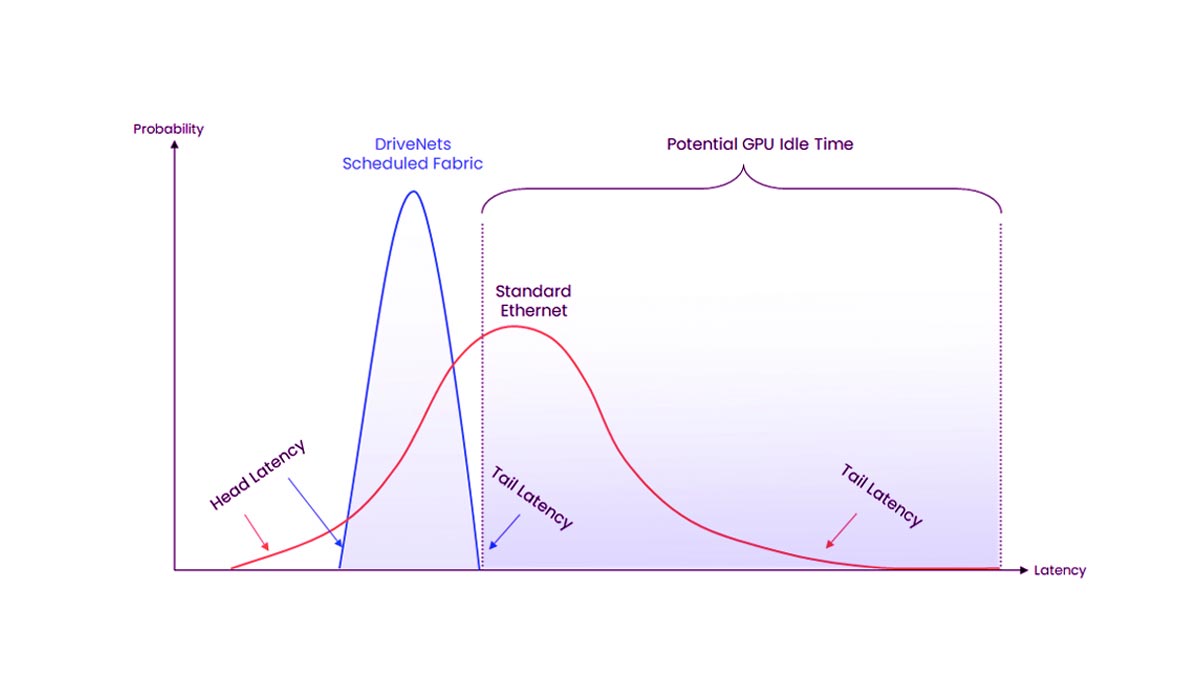
Congestion Control and Lossless Networking
AI workloads are highly sensitive to packet loss and congestion. Even small network disruptions can slow distributed training and leave GPUs idle.
To improve stability, AI fabrics commonly use:
-
RDMA-enabled transport
-
Priority Flow Control (PFC)
-
Explicit Congestion Notification (ECN)
-
Data Center Bridging (DCB)
These technologies help create a more predictable, low-latency environment for GPU communication.
InfiniBand provides built-in congestion management, while Ethernet-based RoCEv2 deployments require careful tuning to maintain lossless behavior.
NCCL, RDMA, and Network Tuning
Application-level optimization is also essential for AI networking performance.
NVIDIA NCCL (NVIDIA Collective Communications Library) is widely used for multi-GPU communication and depends heavily on efficient network transport. Proper RDMA configuration helps reduce CPU overhead and improve GPU-to-GPU data transfer efficiency.
Common optimization areas include:
Together, these network and application-level optimizations help reduce communication overhead and improve distributed AI training scalability.
⭐ AI Cluster Networking and Optical Modules
Optical modules are a core component of modern AI cluster networking. As GPU clusters scale from hundreds to thousands of accelerators, the network must deliver extremely high bandwidth, low latency, and reliable signal integrity across servers and switches. This has made high-speed optical interconnects essential in AI data centers.
Why Optical Modules Matter in AI Fabrics
Distributed AI training generates massive east-west traffic between GPU nodes. Copper cabling alone cannot efficiently support long-distance, high-density 400G and 800G connectivity inside large AI clusters.
Optical modules help solve several critical challenges:
-
High-bandwidth GPU communication
-
Low-latency data transmission
-
Scalable spine-leaf fabric expansion
-
Reduced signal degradation over distance
-
Improved cable management in dense racks
As AI clusters continue growing, optical networking becomes increasingly important for maintaining stable performance and high GPU utilization.
100G, 400G, and 800G Optics in AI Clusters
Modern AI infrastructures are rapidly transitioning from 100G networks toward 400G and 800G fabrics.
1. 100G Optics
100G transceivers are still common in smaller GPU clusters, storage networks, and legacy AI environments.
Typical use cases include:
2. 400G Optics
400G has become the mainstream choice for many enterprise and hyperscale AI deployments because it provides significantly higher bandwidth for distributed GPU communication.
Common 400G optical modules include:
-
QSFP-DD SR8
-
QSFP-DD DR4
-
QSFP-DD FR4
These modules are widely used for spine-to-leaf and leaf-to-server connectivity in modern AI fabrics.
3. 800G Optics
800G networking is emerging in next-generation AI clusters designed for ultra-large model training and high-density GPU deployments.
800G OSFP and QSFP-DD800 transceivers help increase:
-
Network throughput
-
Port density
-
Fabric scalability
-
Future-proofing capacity
QSFP-DD, OSFP, and Breakout Connectivity
Two major form factors dominate AI networking today:
1. QSFP-DD
QSFP-DD modules are widely adopted because they offer high port density and strong compatibility with existing Ethernet ecosystems.
They are commonly used for:
-
100G
-
200G
-
400G
-
800G deployments
2. OSFP
OSFP modules are designed for higher power and thermal performance, making them increasingly popular in 800G AI fabrics.
OSFP is often preferred in:
3. Breakout Options
Breakout connectivity allows one high-speed port to split into multiple lower-speed links, such as:
-
400G to 4×100G
-
800G to 2×400G
-
800G to 8×100G
Breakout designs improve flexibility and help optimize switch port utilization in AI fabrics.
Choosing Optics for AI Cluster Links
Optical module selection depends on link distance, bandwidth requirements, power consumption, and deployment topology.
1. Switch-to-Switch Links
Spine-to-leaf connections usually require:
400G DR4, FR4, and 800G optics are commonly used in these scenarios.
2. Switch-to-Server Links
Leaf-to-GPU server connections are often shorter and may use:
The correct choice depends on rack density and thermal design.
Fiber vs. DAC vs. AOC
|
Technology
|
Advantages
|
Limitations
|
Typical Use Case
|
|
Fiber Optics
|
Long reach, high bandwidth, scalability
|
Higher cost
|
Spine-leaf fabrics
|
|
DAC
|
Low cost, low power
|
Very short distance
|
Same-rack connections
|
|
AOC
|
Lightweight, flexible, longer reach than DAC
|
Higher cost than DAC
|
Cross-rack GPU links
|
In modern AI cluster networking, most large-scale deployments combine fiber optics, DACs, and AOCs to balance cost, density, power efficiency, and scalability.
⭐ Bandwidth Planning for AI Training and Inference
Bandwidth planning is a critical part of AI cluster networking design. Insufficient network bandwidth can reduce GPU utilization, increase training time, and create congestion bottlenecks across the fabric. The correct network capacity depends heavily on workload type, cluster size, and future scaling requirements.
How Workload Type Affects Bandwidth Demand
Different AI workloads generate very different traffic patterns.
1. AI Training Workloads
Distributed AI training creates extremely high east-west traffic because GPUs constantly exchange gradients, tensors, and model parameters during synchronization operations.
Training environments typically require:
Large language model (LLM) training clusters often rely on 400G or 800G fabrics to maintain efficient GPU synchronization.
2. AI Inference Workloads
Inference workloads are usually less bandwidth-intensive because communication between nodes is lower.
Inference networks often prioritize:
-
Fast response time
-
Request scalability
-
Cost efficiency
-
Flexible deployment
In many inference environments, 100G or 400G Ethernet fabrics are sufficient depending on model size and traffic volume.
Single-Node vs Multi-Node Scaling
Bandwidth requirements increase significantly as AI workloads scale across multiple servers.
1. Single-Node AI Systems
Single-node GPU servers mainly rely on internal GPU interconnects such as NVLink or PCIe, reducing dependency on external networking.
These environments typically require less fabric bandwidth.
2. Multi-Node AI Clusters
Multi-node deployments generate much heavier network traffic because GPUs must synchronize data across servers continuously.
As cluster size grows:
-
East-west traffic increases rapidly
-
Congestion risk becomes higher
-
Low-latency fabrics become more important
-
Optical interconnect demand increases
Large distributed training clusters often require non-blocking 400G or 800G spine-leaf architectures.
Planning for Current and Future AI Growth
AI infrastructure requirements are evolving quickly. Many organizations that originally deployed 100G networks are now upgrading to 400G and preparing for 800G scalability.
When planning AI fabrics, it is important to consider:
Designing with future scalability in mind can reduce expensive network redesigns later.
Practical Sizing Rules for 400G and 800G AI Fabrics
Although requirements vary by workload, several practical guidelines are commonly used in modern AI networking.
1. 100G Networks
Suitable for:
2. 400G Networks
Recommended for:
-
Medium-to-large AI training clusters
-
Multi-rack GPU deployments
-
High-performance RoCEv2 fabrics
-
Modern spine-leaf architectures
400G has become the mainstream choice for many enterprise AI data centers.
3. 800G Networks
Best suited for:
-
Hyperscale AI infrastructure
-
Ultra-large distributed training
-
Future-proof GPU fabrics
-
High-density AI switch platforms
800G fabrics help improve scalability, port density, and long-term bandwidth efficiency as AI workloads continue expanding.
⭐ Common AI Cluster Networking Problems and How to Fix Them
Even well-designed AI clusters can experience networking problems that reduce GPU utilization and slow distributed training. Because AI workloads are highly sensitive to latency and congestion, small network issues can quickly impact overall cluster performance.

Below are some of the most common AI cluster networking problems and their practical solutions.
Latency Spikes
Unexpected latency spikes can interrupt GPU synchronization and slow collective communication operations such as All-Reduce.
Common causes include:
To reduce latency spikes:
-
Use non-blocking or low-oversubscription fabrics
-
Enable RDMA where possible
-
Optimize ECMP load balancing
-
Improve GPU and NUMA affinity alignment
-
Monitor switch buffer utilization
Consistent low latency is critical for maintaining efficient distributed AI training.
Packet Loss and Congestion
Packet loss is especially harmful in AI training environments because retransmissions can delay synchronization across thousands of GPUs.
Congestion is often caused by:
Common solutions include:
-
Deploying lossless Ethernet technologies
-
Configuring PFC and ECN correctly
-
Increasing fabric bandwidth
-
Reducing oversubscription ratios
-
Using intelligent congestion control mechanisms
InfiniBand fabrics typically provide built-in congestion management, while RoCEv2 environments require more careful tuning.
Misconfigured RDMA or RoCE
Improper RDMA configuration is one of the most common causes of unstable AI network performance.
Typical issues include:
Symptoms may include:
To improve RDMA stability:
-
Standardize network configuration across the cluster
-
Validate PFC and ECN behavior
-
Use consistent MTU settings
-
Test RDMA performance regularly
-
Monitor NCCL communication efficiency
Driver and Firmware Mismatch Issues
AI clusters depend heavily on compatibility between NICs, switches, GPUs, and operating systems. Firmware mismatches can create unpredictable performance problems or RDMA failures.
Common problem areas include:
-
NIC firmware inconsistencies
-
Switch software incompatibility
-
GPU driver mismatches
-
Unsupported RDMA feature versions
Best practices include:
-
Keeping firmware versions standardized cluster-wide
-
Validating compatibility before upgrades
-
Maintaining documented software baselines
-
Testing updates in staging environments first
Consistent firmware management is essential for stable large-scale AI operations.
Poor Link Utilization Across the Cluster
Some AI clusters experience uneven bandwidth usage where certain links become congested while others remain underutilized.
This is often caused by:
To improve fabric utilization:
-
Optimize spine-leaf topology design
-
Tune ECMP policies
-
Balance traffic paths across switches
-
Monitor flow distribution continuously
-
Use telemetry and fabric analytics tools
Efficient link utilization helps maximize available bandwidth and improve overall AI training scalability.
⭐ AI Cluster Networking FAQ

Q1: What is the best network for an AI cluster?
The best network for an AI cluster depends on workload scale, latency requirements, and budget. Large-scale distributed AI training environments often use InfiniBand because of its ultra-low latency and strong RDMA performance. Enterprise AI deployments commonly choose RoCEv2 over Ethernet for a balance of scalability, cost, and operational flexibility.
Q2: Is InfiniBand better than RoCEv2?
InfiniBand generally delivers lower latency and more mature congestion management for hyperscale AI training clusters. However, RoCEv2 has become a popular alternative because it combines RDMA performance with standard Ethernet infrastructure, reducing deployment cost and improving compatibility with enterprise networks.
For many organizations, RoCEv2 offers the best balance between performance and scalability.
Q3: Do AI clusters need 400G or 800G optics?
Modern AI training clusters increasingly rely on 400G and 800G optical modules to support high-bandwidth GPU communication.
Smaller inference clusters and development environments may still operate efficiently with 100G networking.
Q4: Can Ethernet handle AI training?
Yes. Modern Ethernet fabrics combined with RoCEv2 and RDMA technologies can support large-scale AI training effectively. Many enterprise AI data centers now use high-speed Ethernet with lossless network configurations for distributed GPU workloads.
However, Ethernet-based AI fabrics require careful tuning of technologies such as:
-
PFC (Priority Flow Control)
-
ECN (Explicit Congestion Notification)
-
DCB (Data Center Bridging)
Without proper configuration, congestion and packet loss can reduce training efficiency.
Q5: How do optical modules affect AI cluster performance?
Optical modules directly impact bandwidth, latency, scalability, and signal reliability in AI cluster networking.
High-speed transceivers such as QSFP-DD and OSFP modules enable:
-
400G and 800G connectivity
-
Long-distance spine-leaf communication
-
High-density GPU fabrics
-
Lower signal degradation
-
Better scalability for distributed AI workloads
Choosing the correct optics for switch-to-switch and switch-to-server links helps improve overall AI cluster performance and future scalability.
⭐ Best Practices for Future AI Networking Projects
As AI infrastructure continues moving toward larger GPU clusters and 400G/800G fabrics, network design decisions made today will directly affect long-term scalability, operational stability, and deployment cost. Successful AI cluster networking projects are no longer focused only on raw bandwidth — they also prioritize observability, interoperability, and future optical scalability.

Build for Observability First
AI clusters generate massive amounts of east-west traffic, making visibility and monitoring essential. Modern AI fabrics should include:
-
Real-time telemetry
-
Congestion monitoring
-
RDMA performance analytics
-
GPU communication visibility
-
Switch and optical diagnostics
Early observability helps identify bottlenecks before they impact GPU utilization and training efficiency.
Keep the Design Vendor-Neutral
Vendor lock-in can limit future scalability and increase infrastructure costs. Whenever possible, organizations should design AI fabrics around open Ethernet standards, interoperable optics, and flexible spine-leaf architectures.
A vendor-neutral strategy improves:
Standardize Firmware and Cabling
Firmware inconsistencies are one of the most common causes of AI network instability. Standardizing NIC firmware, switch software, optical modules, and cable types helps reduce unexpected interoperability problems.
Best practices include:
-
Maintaining consistent firmware versions
-
Using validated optical compatibility lists
-
Standardizing DAC, AOC, and fiber deployment
-
Testing upgrades before production rollout
Document Topology and Tuning Parameters
Large AI fabrics can become extremely complex. Proper documentation simplifies troubleshooting and future expansion.
Important items to document include:
Well-documented environments are easier to scale and maintain over time.
Plan for Optical Scaling, Not Just Switch Ports
Future AI growth will require far more than additional switch ports. Optical bandwidth density, power efficiency, and cable management are becoming equally important design factors.
Organizations deploying new AI infrastructure should already be preparing for:
-
400G-to-800G migration paths
-
Higher rack density
-
OSFP and QSFP-DD800 adoption
-
Scalable fiber infrastructure
-
Future ultra-cluster architectures
Choosing the right optical ecosystem early can significantly reduce future upgrade complexity.
As AI cluster networking continues evolving, high-quality optical interconnects and reliable Ethernet components will remain foundational to scalable GPU infrastructure. For organizations planning modern AI fabrics, the LINK-PP Official Store provides a wide range of high-speed optical modules, DAC/AOC solutions, and networking connectivity products designed for enterprise AI, HPC, and data center deployments.
































