

























Chat en direct
Nous sommes là pour vous aider 24h/24 et 7j/7.
Envoyez-nous un message dès maintenant pour une réponse rapide.
Les Catégories
Modules SFP
Services
Assistance
À propos de nous
Ressources


Occupez-vous de vos affaires avec une variété d'options de paiement fiables.
Utilisez le numéro de commande ou le numéro de suivi pour vérifier l'état de l'expédition.
Obtenez votre devis rapidement et bénéficiez d'un service plus professionnel.
Aidez à mieux gérer votre budget et vos dépenses.
Prise en charge des échantillons gratuits, obtenez vos résultats de test efficacement.
Support et service d'équipe professionnels, pour résoudre vos problèmes à temps.
Demandez-nous ce que vous voulez, nous vous aiderons 24h/7 et XNUMXj/XNUMX.
Obtenez votre devis rapidement et offrez-vous un service plus professionnel.
Rencontrez-nous et connaissez notre mission, nos convictions, notre service et plus encore.
Trouvez nos emplacements et connectez-vous étroitement avec nous.
Découvrez comment nous nous soucions de la qualité.
Découvrez les dernières actualités et événements autour l-p.com
Analyse approfondie des guides techniques, des normes industrielles et des informations sur la compatibilité SFP.
Des analyses comparatives détaillées des produits et des analyses côte à côte pour vous aider à choisir le module adapté.
Découvrez des solutions de connectivité concrètes pour les centres de données, les entreprises et les réseaux de télécommunications.
Conseils essentiels pour choisir les débits de données, les distances de transmission et les types de connecteurs.





Avec la croissance exponentielle des modèles d'IA, la mise en réseau est devenue aussi cruciale que les performances des GPU. Les charges de travail d'IA modernes reposent sur des clusters de GPU distribués qui génèrent un trafic est-ouest massif lors de l'entraînement et de l'inférence, rendant indispensable une mise en réseau à faible latence et à large bande passante pour l'efficacité globale du système.
C'est ici que Réseautage de clusters d'IA joue un rôle critique.
Le terme « réseau de clusters d'IA » désigne l'infrastructure réseau haute performance qui connecte les serveurs GPU, les systèmes de stockage et les accélérateurs d'IA au sein des centres de données d'IA et des environnements HPC. Contrairement aux réseaux d'entreprise traditionnels, les clusters d'IA nécessitent une communication ultrarapide entre les nœuds pour prendre en charge les frameworks de calcul distribué tels que NCCL et la communication GPU basée sur RDMA.
Pour réduire les goulots d'étranglement et maximiser l'utilisation du GPU, les infrastructures d'IA modernes utilisent généralement des technologies telles que :
InfiniBand
RoCEv2 et RDMA
Infrastructures Ethernet sans perte
Architectures de réseau épineuse-feuille
Interconnexions optiques 400G et 800G
Au niveau physique, les modules optiques sont devenus un élément clé de la conception des infrastructures d'IA. Les émetteurs-récepteurs haut débit, tels que les modules QSFP-DD et OSFP, permettent une connectivité évolutive de 400G et 800G entre les commutateurs et les serveurs GPU, tout en maintenant une faible latence et une densité de ports élevée.
Dans ce guide, nous expliquerons le fonctionnement des réseaux de clusters d'IA, comparerons les architectures InfiniBand et RoCEv2, examinerons les technologies RDMA et de contrôle de la congestion, et explorerons comment les modules optiques prennent en charge l'évolutivité des clusters d'IA modernes en 2025 et au-delà.
Le réseau de clusters d'IA désigne l'infrastructure réseau haute performance utilisée pour connecter les serveurs GPU, les accélérateurs d'IA, les systèmes de stockage et les commutateurs au sein des centres de données d'IA et des environnements de calcul haute performance (HPC). Son objectif principal est de permettre un échange de données extrêmement rapide entre les nœuds de calcul lors de charges de travail d'IA distribuées.
En termes d'ingénierie pratique, la mise en réseau des clusters d'IA vise à résoudre un problème crucial : garantir l'utilisation optimale des GPU lors des tâches d'entraînement et d'inférence à grande échelle. Les modèles d'IA modernes étant trop volumineux pour fonctionner efficacement sur un seul GPU, voire un seul serveur, les charges de travail sont réparties sur plusieurs nœuds qui doivent synchroniser constamment leurs données. Le réseau devient ainsi partie intégrante du système de calcul, et non plus une simple couche de transport.
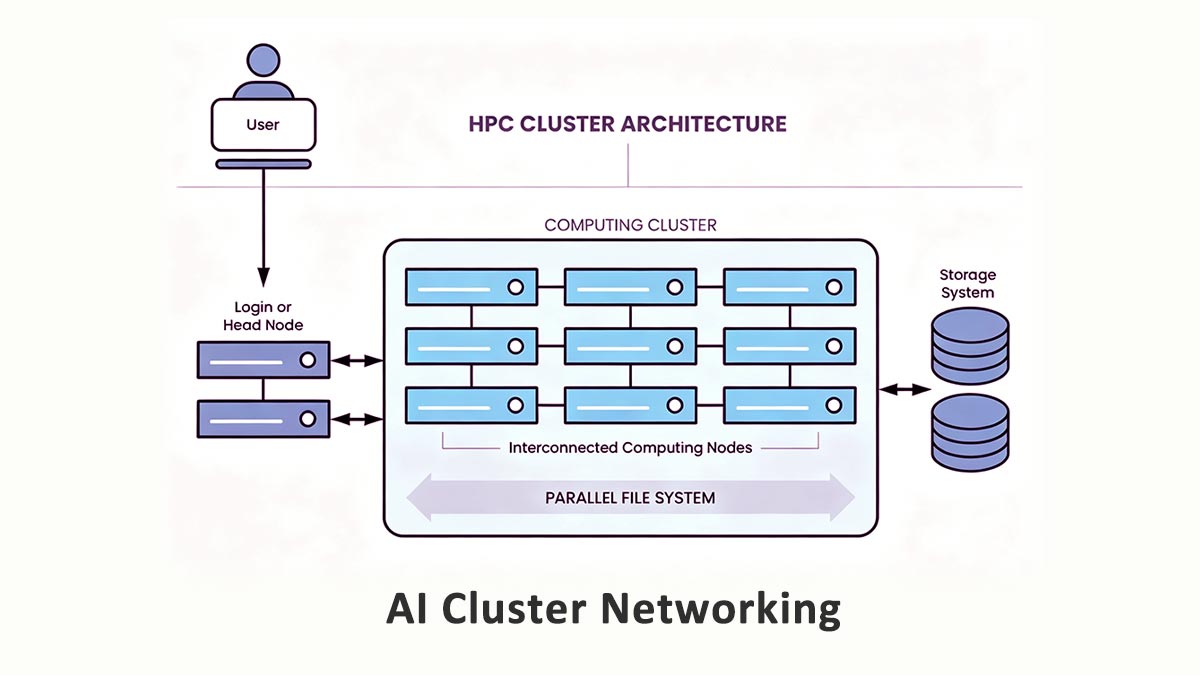
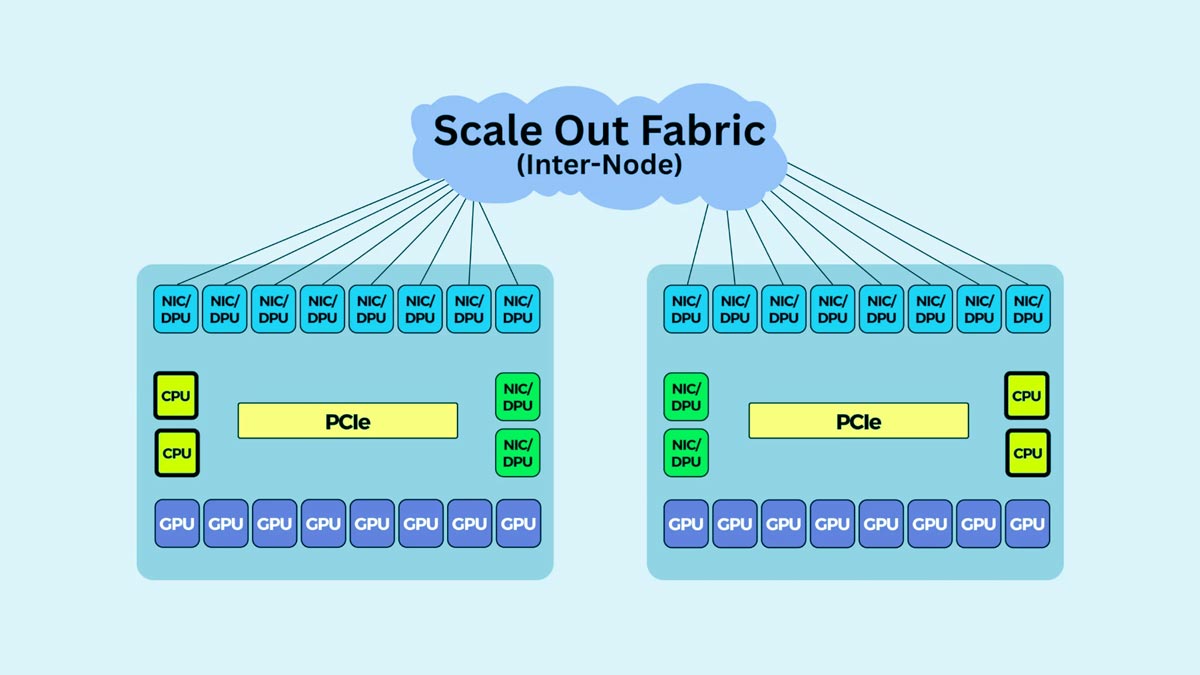
Contrairement aux réseaux d'entreprise classiques qui gèrent principalement la communication entre l'utilisateur et le serveur, les clusters d'IA génèrent des quantités massives de trafic est-ouest — les données se déplaçant latéralement entre les GPU, les serveurs et les systèmes de stockage à l'intérieur du centre de données.
L'entraînement distribué des systèmes d'IA nécessite que les GPU échangent en continu les gradients, les tenseurs, les paramètres du modèle et les données de synchronisation. Lors d'opérations telles que le parallélisme de données, le parallélisme de tenseurs et le parallélisme de pipelines, chaque GPU peut communiquer simultanément avec de nombreux autres GPU.
Cela crée des schémas de trafic est-ouest extrêmement gourmands en bande passante.
Par exemple, lors de l'entraînement de grands modèles de langage (LLM), les GPU effectuent fréquemment des opérations de communication collective telles que :
Réduction totale
Rassemblement général
Diffusez
Réduction de la dispersion
Ces opérations génèrent un trafic inter-nœuds important, très sensible à :
Latence
Perte de paquets
Congestion
Jitter
Sursouscription au réseau
Même de petits retards de synchronisation peuvent laisser des GPU coûteux inactifs, réduisant considérablement l'efficacité du cluster et augmentant le temps d'entraînement.
C’est pourquoi les environnements de mise en réseau de l’IA déploient généralement :
Topologies épine-feuille non bloquantes
Tissus compatibles RDMA
Ethernet sans perte ou InfiniBand
Interconnexions optiques 400G et 800G
mécanismes intelligents de contrôle de la congestion
L'objectif est de minimiser la surcharge de communication et de maintenir des performances prévisibles à faible latence sur l'ensemble du cluster.
Bien que l'entraînement et l'inférence de l'IA reposent tous deux sur des réseaux à haut débit, leurs modèles de trafic et leurs exigences en matière d'infrastructure sont très différents.
Les environnements d'entraînement de l'IA privilégient :
Latence ultra faible
Haut débit
efficacité de synchronisation GPU
Grande capacité de bande passante est-ouest
RDMA et optimisation de la communication collective
Les clusters d'entraînement utilisent souvent des infrastructures InfiniBand ou RoCEv2 avec des modules optiques 400G/800G pour prendre en charge une communication GPU-à-GPU continue à grande échelle.
Les charges de travail d'inférence sont généralement davantage axées sur :
Temps de réponse rapide
Évolutivité pour les requêtes des utilisateurs
Gestion du trafic nord-sud
Rapport coût-efficacité
L'équilibrage de charge
Les clusters d'inférence peuvent ne pas nécessiter le même niveau de synchronisation à très faible latence que les environnements d'entraînement, notamment pour les charges de travail d'inférence mono-nœud ou légèrement distribuées. Dans de nombreux cas, un réseau Ethernet haut débit est suffisant.
Cependant, à mesure que les applications d'inférence distribuée à grande échelle et d'IA générative en temps réel continuent de se développer, les exigences en matière de réseau d'inférence deviennent également plus élevées, notamment pour les architectures de service d'IA multi-nœuds.
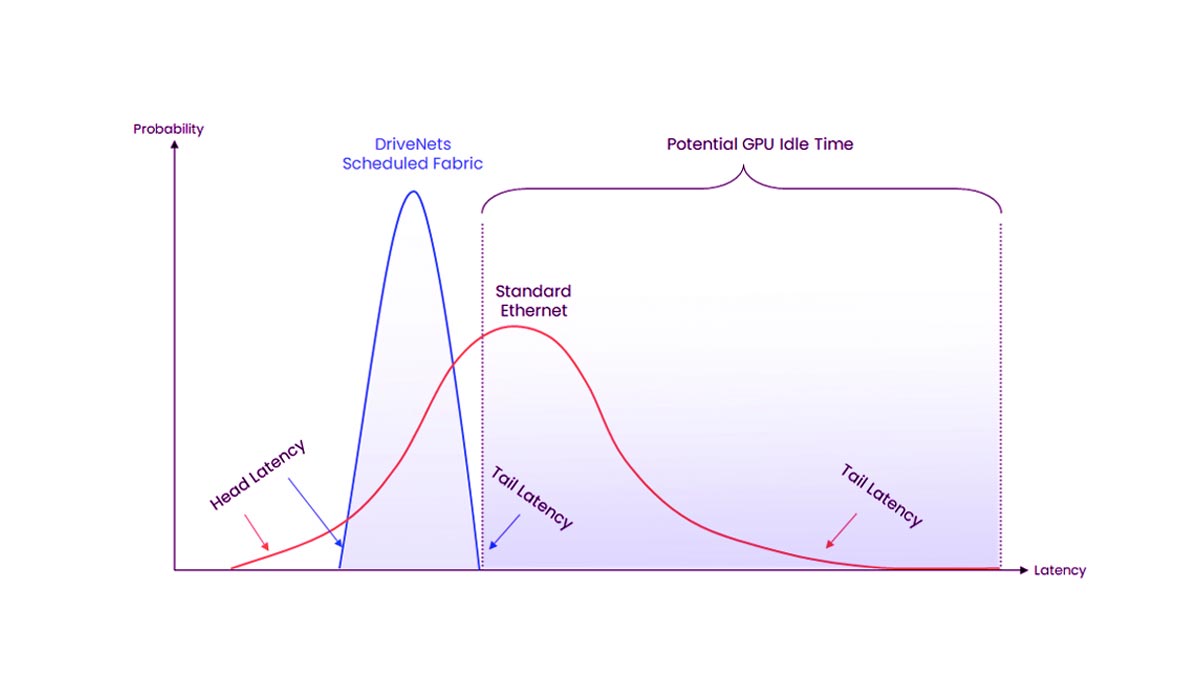
Le choix de l'architecture réseau appropriée pour un cluster d'IA a un impact direct sur l'utilisation du GPU, la latence, l'évolutivité et le coût de déploiement. Aujourd'hui, la plupart des infrastructures d'IA reposent sur trois approches principales : InfiniBand, RoCEv2 et Ethernet standard.
InfiniBand est largement utilisé dans les environnements d'entraînement d'IA à très grande échelle et de calcul haute performance (HPC) grâce à sa latence ultra-faible, son débit élevé et son contrôle avancé de la congestion. Optimisé pour le RDMA et la communication GPU à grande échelle, il est idéal pour les charges de travail d'entraînement d'IA distribuées.
Les principaux avantages incluent :
Latence extrêmement faible
haute efficacité de communication GPU
Performances RDMA solides
Excellente évolutivité pour les grands clusters
Cependant, InfiniBand présente également des coûts plus élevés et une plus grande complexité de déploiement, ce qui le rend plus adapté aux situations suivantes :
grands clusters d'entraînement d'IA
Environnements HPC
Déploiements de GPU multi-racks
RoCEv2 (RDMA sur Ethernet convergé) apporte les fonctionnalités RDMA aux réseaux Ethernet. Il offre un excellent compromis entre performances, évolutivité et coût, tout en s'intégrant plus facilement à l'infrastructure d'entreprise.
Les avantages de RoCEv2 incluent :
Moins cher qu'InfiniBand
Compatibilité Ethernet haut débit
Bonne évolutivité pour les charges de travail d'IA
Intégration d'entreprise simplifiée
Pour garantir des performances stables, RoCEv2 nécessite une configuration appropriée des technologies Ethernet sans perte telles que PFC et ECN.
RoCEv2 est couramment utilisé dans :
clusters d'IA d'entreprise
Infrastructure d'IA dans le cloud
Environnements GPU de moyenne à grande taille
L'Ethernet standard reste une option pratique pour les déploiements d'IA de petite taille et les clusters d'inférence où la synchronisation GPU à très faible latence est moins critique.
Les avantages comprennent:
Coût de déploiement réduit
Simplifiez votre gestion
Large compatibilité
Mise à l'échelle flexible
Les infrastructures Ethernet modernes 100G et 400G peuvent prendre en charge efficacement de nombreuses charges de travail d'inférence IA, même si elles ne peuvent pas égaler les infrastructures basées sur RDMA pour l'entraînement distribué à grande échelle.
|
Caractéristique |
InfiniBand |
RoCEv2 |
Ethernet |
|---|---|---|---|
|
Latence |
Le plus bas |
Très faible |
Modérée |
|
Prise en charge RDMA |
Originaire |
Appareils |
Édition |
|
Prix |
Le plus élevé |
Moyenne |
Le plus bas |
|
Complexité |
Haute |
Moyenne |
Low |
|
Meilleur cas d'utilisation |
Formation à grande échelle en IA |
clusters d'IA d'entreprise |
Inférence et déploiements plus petits |
De manière générale, InfiniBand reste le choix privilégié pour des performances d'entraînement IA maximales, RoCEv2 offre le meilleur équilibre entre coût et évolutivité, et Ethernet standard est souvent suffisant pour les environnements d'IA axés sur l'inférence.
La conception d'une infrastructure d'IA à faible latence est essentielle pour maintenir une utilisation optimale des GPU et un entraînement distribué efficace. Dans les clusters d'IA modernes, le réseau doit supporter un trafic est-ouest massif avec un minimum de congestion, de perte de paquets et de délai de synchronisation.
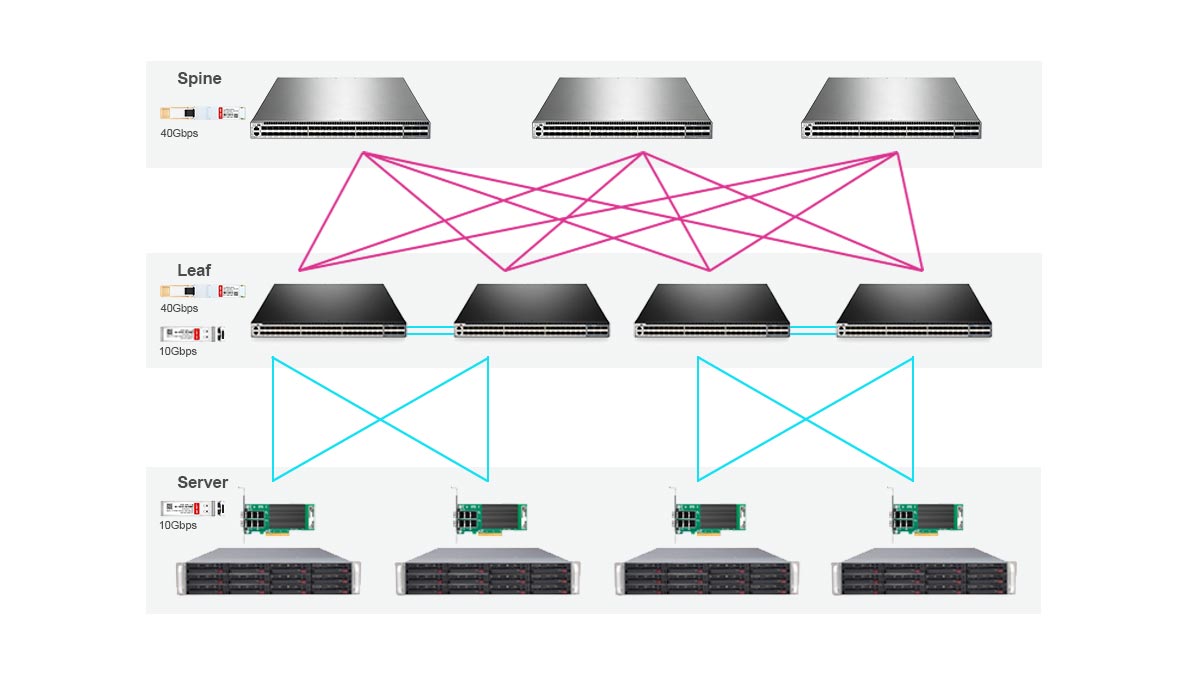
La plupart des clusters d'IA utilisent un topologie colonne vertébrale-feuille car elle assure une communication prévisible à faible latence et une bande passante évolutive sur l'ensemble des nœuds GPU.
Dans cette architecture :
Les commutateurs Leaf se connectent directement aux serveurs GPU.
Les commutateurs centraux interconnectent tous les commutateurs à lames.
Chaque interrupteur à feuille possède des chemins de coût égal vers les autres feuilles
Cette conception minimise les goulots d'étranglement et prend en charge les schémas de trafic est-ouest à large bande passante courants dans l'entraînement de l'IA.
Les déploiements d'IA à grande échelle visent souvent à tissu non bloquant, où le réseau fournit une bande passante suffisante pour éviter les conflits entre les nœuds lors des opérations de communication GPU telles que All-Reduce et All-Gather.
La sursouscription se produit lorsque la bande passante montante disponible est inférieure à la bande passante totale accessible depuis le serveur.
Pour les clusters d'entraînement d'IA, une faible sursouscription est importante car les charges de travail distribuées des GPU génèrent un trafic inter-nœuds continu. Une sursouscription élevée peut augmenter la latence et réduire l'efficacité de l'entraînement.
Les approches courantes incluent :
Conceptions non bloquantes 1:1 pour les grands clusters d'entraînement d'IA
Faibles taux de sursouscription pour les déploiements GPU de taille moyenne
Sursouscription plus élevée pour les environnements axés sur l'inférence
Le ratio idéal dépend du type de charge de travail, du nombre de GPU et des contraintes budgétaires.
Les charges de travail d'IA sont extrêmement sensibles aux pertes de paquets et à la congestion du réseau. Même de petites perturbations peuvent ralentir l'entraînement distribué et laisser les GPU inactifs.
Pour améliorer la stabilité, les tissus à IA utilisent généralement :
Transport compatible RDMA
Contrôle de flux prioritaire (PFC)
Notification explicite de congestion (ECN)
Pont de centre de données (DCB)
Ces technologies contribuent à créer un environnement plus prévisible et à faible latence pour la communication GPU.
InfiniBand offre une gestion intégrée de la congestion, tandis que les déploiements RoCEv2 basés sur Ethernet nécessitent un réglage précis pour maintenir un comportement sans perte.
L'optimisation au niveau applicatif est également essentielle pour les performances des réseaux d'IA.
La bibliothèque NVIDIA NCCL (NVIDIA Collective Communications Library) est largement utilisée pour la communication multi-GPU et repose fortement sur un transport réseau efficace. Une configuration RDMA appropriée contribue à réduire la charge du processeur et à améliorer l'efficacité des transferts de données entre GPU.
Les domaines d'optimisation courants comprennent :
Réglage de la topologie NCCL
Configuration de la file d'attente RDMA
Affinité GPU et alignement NUMA
Optimisation MTU
Équilibrage des voies de circulation
Ensemble, ces optimisations au niveau du réseau et des applications contribuent à réduire la surcharge de communication et à améliorer l'évolutivité de l'entraînement de l'IA distribuée.
Les modules optiques sont un élément essentiel des réseaux modernes de clusters d'IA. À mesure que les clusters de GPU passent de centaines à des milliers d'accélérateurs, le réseau doit garantir une bande passante extrêmement élevée, une faible latence et une intégrité du signal fiable entre les serveurs et les commutateurs. C'est pourquoi les interconnexions optiques à haut débit sont devenues indispensables dans les centres de données d'IA.
L'entraînement distribué des IA génère un trafic est-ouest massif entre les nœuds GPU. Le câblage en cuivre seul ne peut pas supporter efficacement la connectivité longue distance et haute densité 400G et 800G au sein des grands clusters d'IA.
Les modules optiques contribuent à résoudre plusieurs défis critiques :
Communication GPU à large bande passante
Transmission de données à faible latence
Extension évolutive du tissu de la colonne vertébrale et des feuilles
Dégradation du signal réduite sur la distance
Gestion améliorée des câbles dans les baies denses
À mesure que les clusters d'IA continuent de croître, les réseaux optiques deviennent de plus en plus importants pour maintenir des performances stables et une utilisation élevée des GPU.
Les infrastructures modernes d'IA évoluent rapidement des réseaux 100G vers les réseaux 400G et 800G.
Les émetteurs-récepteurs 100G restent courants dans les petits clusters GPU, les réseaux de stockage et les environnements d'IA existants.
Les cas d'utilisation typiques incluent :
petits groupes d'entraînement d'IA
Réseaux d'inférence
interconnexions de stockage
Déploiements d'IA en périphérie
Le 400G est devenu le choix courant pour de nombreux déploiements d'IA d'entreprise et à très grande échelle, car il offre une bande passante nettement supérieure pour la communication GPU distribuée.
Les modules optiques 400G courants comprennent :
QSFP-DD SR8
QSFP-DD DR4
QSFP-DD FR4
Ces modules sont largement utilisés pour la connectivité spine-to-leaf et leaf-to-server dans les architectures d'IA modernes.
La technologie de réseau 800G émerge dans les clusters d'IA de nouvelle génération conçus pour l'entraînement de modèles ultra-larges et les déploiements de GPU haute densité.
Les émetteurs-récepteurs OSFP 800G et QSFP-DD800 contribuent à augmenter :
Débit réseau
Densité des ports
Évolutivité du tissu
Capacité de pérennisation
Deux grands formats dominent aujourd'hui les réseaux d'IA :
Les modules QSFP-DD sont largement adoptés car ils offrent une densité de ports élevée et une forte compatibilité avec les écosystèmes Ethernet existants.
Ils sont couramment utilisés pour :
100G
200G
400G
Déploiements 800G
Les modules OSFP sont conçus pour offrir une puissance et des performances thermiques supérieures, ce qui les rend de plus en plus populaires dans les architectures IA 800G.
OSFP est souvent préféré dans :
clusters d'IA hyperscale
Environnements de réseau GPU haute puissance
Plateformes de commutation à ultra-haute densité
La connectivité de dérivation permet à un port haut débit de se diviser en plusieurs liaisons à débit inférieur, telles que :
400 g à 4 × 100 g
800 g à 2 × 400 g
800 g à 8 × 100 g
Les conceptions de type « breakout » améliorent la flexibilité et contribuent à optimiser l'utilisation des ports de commutation dans les architectures d'IA.
Le choix du module optique dépend de la distance de liaison, des besoins en bande passante, de la consommation d'énergie et de la topologie de déploiement.
Les connexions entre la colonne vertébrale et les feuilles nécessitent généralement :
Bande passante plus élevée
Portée plus longue
Fibre monomode pour les déploiements à grande échelle
Les optiques 400G DR4, FR4 et 800G sont couramment utilisées dans ces scénarios.
Les connexions entre les serveurs Leaf et le GPU sont souvent plus courtes et peuvent utiliser :
Câbles DAC pour courtes distances
AOC pour la portée moyenne
Optiques multimodes SR pour des configurations de rack flexibles
Le choix approprié dépend de la densité du rack et de la conception thermique.
|
Technologie |
Avantages |
Limites |
Cas d'utilisation typique |
|---|---|---|---|
|
fibre optique |
Longue portée, bande passante élevée, évolutivité |
Coût plus élevé |
Tissus à motif de feuille dorsale |
|
DAC |
Faible coût, faible consommation d'énergie |
très courte distance |
Connexions du même rack |
|
AOC |
Léger, flexible, portée supérieure à celle d'un DAC |
Plus coûteux qu'un DAC |
Liaisons GPU entre racks |
Dans les réseaux modernes de clusters d'IA, la plupart des déploiements à grande échelle combinent fibre optique, DAC et AOC pour équilibrer coût, densité, efficacité énergétique et évolutivité.
La planification de la bande passante est un élément crucial de la conception des réseaux des clusters d'IA. Une bande passante insuffisante peut réduire l'utilisation des GPU, augmenter le temps d'entraînement et créer des goulots d'étranglement au sein du réseau. La capacité réseau appropriée dépend fortement du type de charge de travail, de la taille du cluster et des besoins futurs en matière d'évolutivité.
Les différentes charges de travail d'IA génèrent des modèles de trafic très différents.
L'entraînement distribué de l'IA crée un trafic est-ouest extrêmement élevé car les GPU échangent constamment des gradients, des tenseurs et des paramètres de modèle lors des opérations de synchronisation.
Les environnements de formation nécessitent généralement :
Débit ultra-élevé
Faible latence
Communication via RDMA
faibles taux de sursouscription
Les grands clusters d'entraînement de modèles de langage (LLM) s'appuient souvent sur des réseaux 400G ou 800G pour maintenir une synchronisation GPU efficace.
Les charges de travail d'inférence sont généralement moins gourmandes en bande passante car la communication entre les nœuds est moindre.
Les réseaux d'inférence privilégient souvent :
Temps de réponse rapide
Évolutivité de la demande
Rapport coût-efficacité
Déploiement flexible
Dans de nombreux environnements d'inférence, les réseaux Ethernet 100G ou 400G sont suffisants en fonction de la taille du modèle et du volume de trafic.
Les besoins en bande passante augmentent considérablement à mesure que les charges de travail d'IA s'étendent sur plusieurs serveurs.
Les serveurs GPU à nœud unique s'appuient principalement sur des interconnexions GPU internes telles que NVLink ou PCIe, réduisant ainsi la dépendance au réseau externe.
Ces environnements nécessitent généralement une bande passante réseau plus faible.
Les déploiements multi-nœuds génèrent un trafic réseau beaucoup plus important car les GPU doivent synchroniser les données entre les serveurs en permanence.
À mesure que la taille du groupe augmente :
Le trafic est-ouest augmente rapidement
Le risque de congestion augmente
Les infrastructures à faible latence prennent de l'importance.
La demande d'interconnexions optiques augmente
Les grands clusters d'entraînement distribués nécessitent souvent des architectures spine-leaf non bloquantes de 400G ou 800G.
Les besoins en infrastructure d'IA évoluent rapidement. De nombreuses organisations ayant initialement déployé des réseaux 100G migrent désormais vers le 400G et se préparent à une évolutivité jusqu'au 800G.
Lors de la planification des infrastructures d'IA, il est important de prendre en compte :
Extension future des GPU
Augmentation de la taille des modèles
Densité de rack plus élevée
voies de mise à niveau des modules optiques
Puissance de commutation et capacité de refroidissement
Concevoir en tenant compte de l'évolutivité future peut réduire les coûts liés aux refontes ultérieures du réseau.
Bien que les exigences varient en fonction de la charge de travail, plusieurs lignes directrices pratiques sont couramment utilisées dans les réseaux d'IA modernes.
Convient pour:
petits clusters de GPU
Environnements d'inférence
Systèmes de développement et de test
Recommandé pour:
Clusters d'entraînement d'IA de taille moyenne à grande
Déploiements de GPU multi-racks
Tissus RoCEv2 haute performance
Architectures modernes à épine dorsale et à feuilles
La norme 400G est devenue le choix courant pour de nombreux centres de données d'IA d'entreprise.
Idéal pour:
Infrastructure d'IA à très grande échelle
Formation distribuée à très grande échelle
Des architectures GPU à l'épreuve du temps
Plateformes de commutation IA haute densité
Les infrastructures 800G contribuent à améliorer l'évolutivité, la densité des ports et l'efficacité de la bande passante à long terme à mesure que les charges de travail d'IA continuent de croître.
Même les clusters d'IA les mieux conçus peuvent rencontrer des problèmes de réseau qui réduisent l'utilisation du GPU et ralentissent l'entraînement distribué. Les charges de travail d'IA étant très sensibles à la latence et à la congestion, de petits problèmes de réseau peuvent rapidement impacter les performances globales du cluster.

Vous trouverez ci-dessous quelques-uns des problèmes de mise en réseau des clusters d'IA les plus courants et leurs solutions pratiques.
Des pics de latence inattendus peuvent interrompre la synchronisation du GPU et ralentir les opérations de communication collective telles que All-Reduce.
Les causes courantes incluent:
Sursouscription au réseau
Liaisons épine-feuille congestionnées
Politiques QoS inappropriées
Charge d'interruptions du processeur élevée
Répartition inégale du trafic
Pour réduire les pics de latence :
Utilisez des tissus non bloquants ou à faible sursouscription.
Activez RDMA lorsque c'est possible.
Optimisation de l'équilibrage de charge ECMP
Amélioration de l'alignement d'affinité GPU et NUMA
Surveiller l'utilisation du tampon du commutateur
Une latence faible et constante est essentielle pour maintenir un entraînement efficace de l'IA distribuée.
La perte de paquets est particulièrement néfaste dans les environnements d'entraînement de l'IA car les retransmissions peuvent retarder la synchronisation entre des milliers de GPU.
La congestion est souvent causée par :
Circulation dense est-ouest
Bande passante montante insuffisante
Mauvaise gestion des files d'attente
Circulation dense pendant les opérations collectives
Les solutions courantes incluent :
Déploiement des technologies Ethernet sans perte
Configurer correctement le PFC et l'ECN
Augmentation de la bande passante du réseau
Réduire les taux de sursouscription
Utilisation de mécanismes intelligents de contrôle de la congestion
Les réseaux InfiniBand intègrent généralement une gestion de la congestion, tandis que les environnements RoCEv2 nécessitent un réglage plus précis.
Une configuration RDMA incorrecte est l'une des causes les plus fréquentes d'instabilité des performances des réseaux d'IA.
Les problèmes typiques incluent :
Paramètres MTU incorrects
mauvaise configuration du PFC
Configuration DCB incorrecte
déséquilibre de la file d'attente RDMA
Paramètres de commutation incompatibles
Les symptômes peuvent inclure:
Instabilité de la communication GPU
Faibles performances NCCL
Pertes de paquets inattendues
Latence élevée pendant l'entraînement distribué
Pour améliorer la stabilité du RDMA :
Standardiser la configuration réseau au sein du cluster
Valider le comportement du PFC et de l'ECN
Utilisez des paramètres MTU cohérents
Tester régulièrement les performances RDMA
Surveiller l'efficacité de la communication NCCL
Les clusters d'IA dépendent fortement de la compatibilité entre les cartes réseau, les commutateurs, les GPU et les systèmes d'exploitation. Des incompatibilités de firmware peuvent engendrer des problèmes de performance imprévisibles ou des défaillances RDMA.
Les problèmes courants comprennent :
Incohérences du firmware de la carte réseau
Incompatibilité logicielle du commutateur
incompatibilités des pilotes de GPU
Versions de fonctionnalités RDMA non prises en charge
Les meilleures pratiques incluent :
Maintenir des versions de firmware standardisées à l'échelle du cluster
Valider la compatibilité avant les mises à niveau
Maintien des référentiels logiciels documentés
Tester les mises à jour dans des environnements de préproduction au préalable
Une gestion cohérente du firmware est essentielle pour des opérations d'IA à grande échelle stables.
Certains clusters d'IA connaissent une utilisation inégale de la bande passante, certaines liaisons étant saturées tandis que d'autres restent sous-utilisées.
Cela est souvent dû à :
Hachage ECMP inefficace
Conception topologique médiocre
Points chauds du trafic
Chemins de communication GPU déséquilibrés
Pour améliorer l'utilisation des tissus :
Optimisation de la conception de la topologie épine-feuille
Ajuster les politiques ECMP
Équilibrer les flux de trafic à travers les commutateurs
Surveiller en continu la distribution du débit
Utilisez les outils de télémétrie et d'analyse du réseau.
L'utilisation efficace des liens permet de maximiser la bande passante disponible et d'améliorer l'évolutivité globale de l'entraînement de l'IA.

Le choix du réseau optimal pour un cluster d'IA dépend de la charge de travail, des exigences en matière de latence et du budget. Les environnements d'entraînement d'IA distribués à grande échelle utilisent souvent InfiniBand en raison de sa latence ultra-faible et de ses excellentes performances RDMA. Les déploiements d'IA en entreprise privilégient généralement RoCEv2 à Ethernet pour un bon compromis entre évolutivité, coût et flexibilité opérationnelle.
InfiniBand offre généralement une latence plus faible et une gestion de la congestion plus performante pour les clusters d'entraînement d'IA à très grande échelle. Cependant, RoCEv2 est devenu une alternative populaire car il combine les performances RDMA avec une infrastructure Ethernet standard, réduisant ainsi les coûts de déploiement et améliorant la compatibilité avec les réseaux d'entreprise.
Pour de nombreuses organisations, RoCEv2 offre le meilleur équilibre entre performance et évolutivité.
Les clusters d'entraînement d'IA modernes s'appuient de plus en plus sur des modules optiques 400G et 800G pour prendre en charge la communication GPU à large bande passante.
Les solutions optiques 400G sont désormais courantes dans les déploiements d'IA de moyenne à grande échelle.
Les optiques 800G sont principalement utilisées dans les infrastructures hyperscale et les réseaux d'IA de nouvelle génération.
Les petits clusters d'inférence et les environnements de développement peuvent toujours fonctionner efficacement avec un réseau 100G.
Oui. Les infrastructures Ethernet modernes, associées aux technologies RoCEv2 et RDMA, permettent de prendre en charge efficacement l'entraînement d'IA à grande échelle. De nombreux centres de données d'IA d'entreprise utilisent désormais l'Ethernet haut débit avec des configurations réseau sans perte pour les charges de travail GPU distribuées.
Cependant, les infrastructures d'IA basées sur Ethernet nécessitent un réglage précis de technologies telles que :
PFC (Contrôle de flux prioritaire)
ECN (Notification explicite de congestion)
DCB (Pont de centre de données)
Sans une configuration adéquate, la congestion et la perte de paquets peuvent réduire l'efficacité de l'entraînement.
Les modules optiques ont un impact direct sur la bande passante, la latence, l'évolutivité et la fiabilité du signal dans les réseaux de clusters d'IA.
Les émetteurs-récepteurs haut débit tels que les modules QSFP-DD et OSFP permettent :
Connectivité 400G et 800G
Communication à longue distance entre la colonne vertébrale et les feuilles
Tissus GPU haute densité
Dégradation du signal plus faible
Meilleure évolutivité pour les charges de travail d'IA distribuées
Choisir les optiques appropriées pour les liaisons entre commutateurs et entre commutateurs et serveurs contribue à améliorer les performances globales du cluster d'IA et son évolutivité future.
À mesure que l'infrastructure d'IA évolue vers des clusters GPU plus importants et des réseaux 400G/800G, les décisions de conception réseau prises aujourd'hui auront un impact direct sur l'évolutivité à long terme, la stabilité opérationnelle et le coût de déploiement. Les projets de mise en réseau de clusters d'IA performants ne se concentrent plus uniquement sur la bande passante brute ; ils privilégient également l'observabilité, l'interopérabilité et l'évolutivité optique future.

Les clusters d'IA génèrent un trafic est-ouest massif, rendant la visibilité et la surveillance essentielles. Les infrastructures d'IA modernes doivent inclure :
Télémétrie en temps réel
Surveillance de la congestion
Analyse des performances RDMA
visibilité de la communication GPU
Diagnostic des commutateurs et des optiques
L'observation précoce permet d'identifier les goulots d'étranglement avant qu'ils n'affectent l'utilisation du GPU et l'efficacité de l'entraînement.
La dépendance vis-à-vis d'un fournisseur unique peut limiter l'évolutivité future et augmenter les coûts d'infrastructure. Dans la mesure du possible, les organisations devraient concevoir leurs infrastructures d'IA autour de normes Ethernet ouvertes, d'optiques interopérables et d'architectures spine-leaf flexibles.
Une stratégie neutre vis-à-vis des fournisseurs améliore :
Flexibilité matérielle
Options de mise à niveau
Contrôle des coûts à long terme
Compatibilité multi-fournisseurs
Les incohérences de micrologiciel constituent l'une des causes les plus fréquentes d'instabilité des réseaux d'IA. La standardisation du micrologiciel des cartes réseau, des logiciels de commutation, des modules optiques et des types de câbles contribue à réduire les problèmes d'interopérabilité inattendus.
Les meilleures pratiques incluent :
Maintien de versions de firmware cohérentes
Utilisation de listes de compatibilité optique validées
Normalisation du déploiement des DAC, des AOC et de la fibre optique
Tests des mises à jour avant leur déploiement en production
Les infrastructures d'IA de grande envergure peuvent devenir extrêmement complexes. Une documentation adéquate simplifie le dépannage et les extensions futures.
Les éléments importants à documenter comprennent :
Conception topologique épine-feuille
Paramètres RDMA et RoCE
Politiques ECMP
Ratios de sursouscription
plans de déploiement des modules optiques
paramètres de réglage NCCL
Les environnements bien documentés sont plus faciles à faire évoluer et à maintenir dans le temps.
Le développement futur de l'IA nécessitera bien plus que de simples ports de commutation supplémentaires. La densité de bande passante optique, l'efficacité énergétique et la gestion des câbles deviennent des facteurs de conception tout aussi importants.
Les organisations qui déploient une nouvelle infrastructure d'IA devraient déjà se préparer à :
Voies de migration de 400G à 800G
Densité de rack plus élevée
Adoption des modules OSFP et QSFP-DD800
Infrastructure de fibre évolutive
Architectures ultra-cluster du futur
Choisir le bon écosystème optique dès le départ peut réduire considérablement la complexité des futures mises à niveau.
À mesure que les réseaux de clusters d'IA évoluent, les interconnexions optiques de haute qualité et les composants Ethernet fiables demeurent essentiels à une infrastructure GPU évolutive. Pour les organisations qui planifient des architectures d'IA modernes, LINK-PP Boutique officielle propose une large gamme de modules optiques haute vitesse, de solutions DAC/AOC et de produits de connectivité réseau conçus pour les déploiements d'IA, de HPC et de centres de données en entreprise.

Connectez-vous ou créez un compte pour suivre votre demande en ligne.