
AIモデルの規模が拡大し続けるにつれ、ネットワークはGPUのパフォーマンスと同様に重要になってきています。最新のAIワークロードは分散型GPUクラスタに依存しており、トレーニングや推論中に膨大な東西トラフィックが発生するため、システム全体の効率性を確保するには、低遅延かつ高帯域幅のネットワークが不可欠です。
これはどこですか? AIクラスターネットワーク 重要な役割を果たします。
AIクラスタネットワークとは、AIデータセンターやHPC環境内でGPUサーバー、ストレージシステム、AIアクセラレーターを接続する高性能ネットワークインフラストラクチャを指します。従来のエンタープライズネットワークとは異なり、AIクラスタでは、NCCLやRDMAベースのGPU通信といった分散コンピューティングフレームワークをサポートするために、ノード間の超高速通信が求められます。
ボトルネックを軽減し、GPUの利用率を最大化するために、最新のAIファブリックでは一般的に次のような技術が使用されています。
-
-
RoCEv2とRDMA
-
ロスレスイーサネットファブリック
-
スパインリーフ型ネットワークアーキテクチャ
-
400Gおよび800G光インターコネクト
物理層においては、光モジュールがAIインフラストラクチャ設計の重要な要素となっています。QSFP-DDやOSFPモジュールなどの高速トランシーバーは、低遅延と高ポート密度を維持しながら、スイッチとGPUサーバー間の拡張性の高い400Gおよび800G接続を実現します。
このガイドでは、AIクラスタネットワークの仕組み、InfiniBandとRoCEv2のアーキテクチャの比較、RDMAと輻輳制御技術の検証、そして光モジュールが2025年以降の最新のAIクラスタのスケーラビリティをどのようにサポートするかについて解説します。
⭐ AIクラスタネットワークとは?
AIクラスタネットワークとは、AIデータセンターや高性能コンピューティング(HPC)環境において、GPUサーバー、AIアクセラレーター、ストレージシステム、スイッチなどを接続するために使用される高性能ネットワークファブリックを指します。その主な目的は、分散AIワークロード実行時に、計算ノード間で極めて高速なデータ交換を実現することです。
実用的なエンジニアリングの観点から見ると、AIクラスタネットワークは、大規模なトレーニングや推論タスク中にGPUを最大限に活用するという、重要な課題を解決するために設計されています。現代のAIモデルは、単一のGPUや単一のサーバーで効率的に実行するには大きすぎるため、ワークロードは複数のノードに分散され、ノード間で常にデータの同期を行う必要があります。そのため、ネットワークは単なるトランスポート層ではなく、コンピューティングシステム自体の一部となるのです。
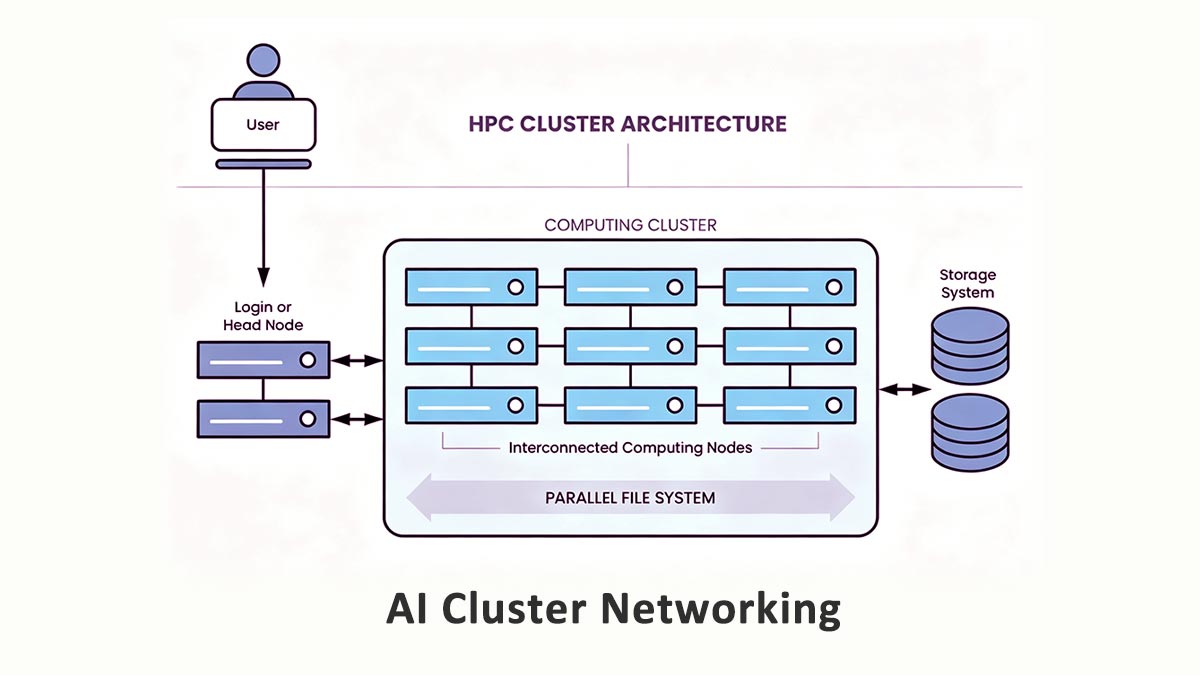
ユーザーとサーバー間の通信を主に処理する従来のエンタープライズネットワークとは異なり、AIクラスターは膨大な量の 東西交通 ―データセンター内のGPU、サーバー、ストレージシステム間でデータが横方向に移動する。
東西方向の交通量がAIトレーニングで主流となる理由
分散型AIトレーニングでは、GPU間で勾配、テンソル、モデルパラメータ、同期データを継続的に交換する必要があります。データ並列処理、テンソル並列処理、パイプライン並列処理などの処理中、各GPUは他の多数のGPUと同時に通信を行う可能性があります。
これにより、極めて帯域幅を大量に消費する東西方向のトラフィックパターンが生み出される。
例えば、大規模言語モデル(LLM)のトレーニング中、GPUは次のような集団的な通信操作を頻繁に実行します。
これらの操作は、ノード間のトラフィックを大量に発生させ、以下の要因に非常に敏感です。
-
レイテンシ
-
パケットロス
-
混雑
-
ジッタ
-
ネットワークの過剰利用
同期にわずかな遅延が生じるだけでも、高価なGPUがアイドル状態になり、クラスタの効率が著しく低下し、トレーニング時間が長くなる可能性があります。
このため、AIネットワーク環境では一般的に以下のものが導入されます。
-
非ブロッキング型スパインリーフトポロジー
-
RDMA対応ファブリック
-
ロスレスイーサネットまたはインフィニバンド
-
400Gおよび800G光インターコネクト
-
インテリジェントな混雑制御メカニズム
目標は、通信オーバーヘッドを最小限に抑え、クラスタ全体で予測可能な低遅延パフォーマンスを維持することです。
トレーニングと推論におけるネットワーク要件
AIのトレーニングとAIの推論はどちらも高速ネットワークに依存するが、そのトラフィックパターンとインフラ要件は大きく異なる。
1. AIトレーニングネットワーク
AIトレーニング環境では、以下の点を優先します。
-
超低レイテンシ
-
ハイスループット
-
GPU同期効率
-
東西方向の帯域幅容量が大きい
-
RDMAと集団通信の最適化
トレーニングクラスタでは、大規模なGPU間通信を継続的にサポートするために、InfiniBandまたはRoCEv2ファブリックと400G/800G光モジュールがよく使用されます。
2. AI推論ネットワーク
推論ワークロードは通常、以下の点に重点を置いています。
-
速い応答時間
-
ユーザーリクエストに対する拡張性
-
南北交通の処理
-
コスト効率
-
ロードバランシング
推論クラスタは、特に単一ノードまたは軽度分散の推論ワークロードの場合、トレーニング環境ほどの超低遅延同期を必要としない場合があります。多くの場合、高速イーサネットファブリックで十分です。
しかし、大規模な分散推論やリアルタイム生成型AIアプリケーションが拡大し続けるにつれて、推論ネットワークの要件もますます厳しくなっており、特にマルチノードAIサービスアーキテクチャにおいてはその傾向が顕著である。
⭐ AIクラスタネットワークアーキテクチャ:InfiniBand、RoCEv2、およびイーサネット
適切なAIクラスタネットワークアーキテクチャを選択することは、GPU利用率、レイテンシ、拡張性、および導入コストに直接影響を与えます。現在、ほとんどのAIインフラストラクチャは、InfiniBand、RoCEv2、および標準イーサネットという3つの主要なアプローチに基づいて構築されています。
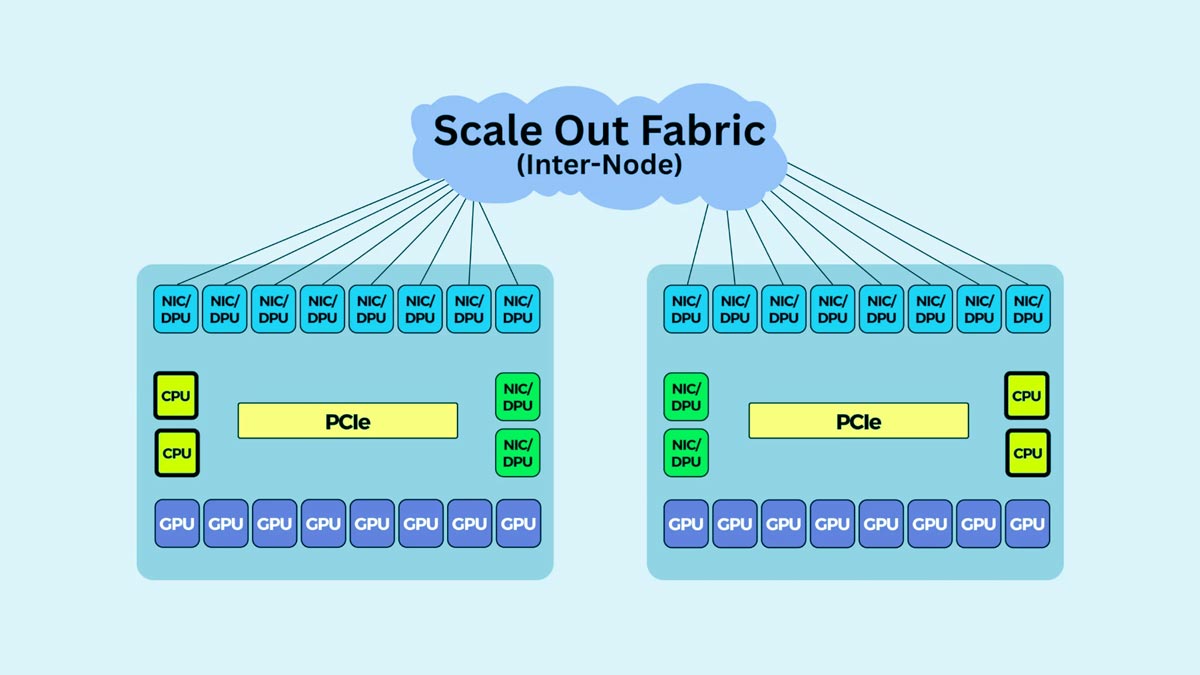
InfiniBandは、超低遅延、高スループット、高度な輻輳制御を実現するため、ハイパースケールAIトレーニングやHPC環境で広く利用されています。RDMAと大規模GPU通信に最適化されているため、分散型AIトレーニングワークロードに最適です。
主な利点は次のとおりです。
-
極めて低いレイテンシ
-
高いGPU通信効率
-
強力なRDMA性能
-
大規模クラスター向けの優れた拡張性
しかし、InfiniBandはコストが高く、導入も複雑であるため、以下のような用途に最も適しています。
-
大規模AIトレーニングクラスター
-
HPC環境
-
マルチラックGPU展開
RoCEv2
RoCEv2(RDMA over Converged Ethernet)は、イーサネットネットワークにRDMA機能をもたらします。パフォーマンス、拡張性、コストのバランスに優れ、企業インフラとの統合も容易です。
RoCEv2の利点は以下のとおりです。
-
InfiniBandよりも低コスト
-
高速イーサネット対応
-
AIワークロードに対する優れた拡張性
-
企業統合が容易になる
安定したパフォーマンスを実現するには、RoCEv2ではPFCやECNなどのロスレスイーサネット技術を適切に設定する必要があります。
RoCEv2は一般的に以下の用途で使用されます。
-
エンタープライズAIクラスター
-
クラウドAIインフラストラクチャ
-
中規模から大規模のGPU環境
標準イーサネット
標準イーサネットは、超低遅延のGPU同期がそれほど重要ではない小規模なAI導入環境や推論クラスタにおいては、依然として実用的な選択肢である。
利点は次のとおりです。
-
導入コストの低減
-
管理の簡素化
-
幅広い互換性
-
柔軟なスケーリング
最新の100Gおよび400Gイーサネットファブリックは、多くのAI推論ワークロードを効果的にサポートできますが、大規模な分散トレーニングにおいては、RDMAベースのファブリックには及ばない場合があります。
InfiniBand vs. RoCEv2 vs. Ethernet
|
機能
|
|
RoCEv2
|
イーサネット
|
|
レイテンシ
|
最低
|
非常に低い
|
穏健派
|
|
RDMA サポート
|
ネイティブ
|
サポート
|
限定的
|
|
費用
|
最高
|
技法
|
最低
|
|
複雑
|
ハイ
|
技法
|
ロー
|
|
最適な使用例
|
大規模AIトレーニング
|
エンタープライズAIクラスター
|
推論と小規模な展開
|
一般的に、AIトレーニングのパフォーマンスを最大限に引き出すにはInfiniBandが依然として最良の選択肢であり、RoCEv2はコストと拡張性のバランスが最も優れており、推論に重点を置いたAI環境では標準イーサネットで十分な場合が多い。
⭐ 低遅延AIファブリックの設計方法
低遅延のAIファブリックを設計することは、高いGPU利用率と効率的な分散トレーニングを維持するために不可欠です。最新のAIクラスタでは、ネットワークは膨大な東西トラフィックを最小限の輻輳、パケット損失、同期遅延で処理する必要があります。
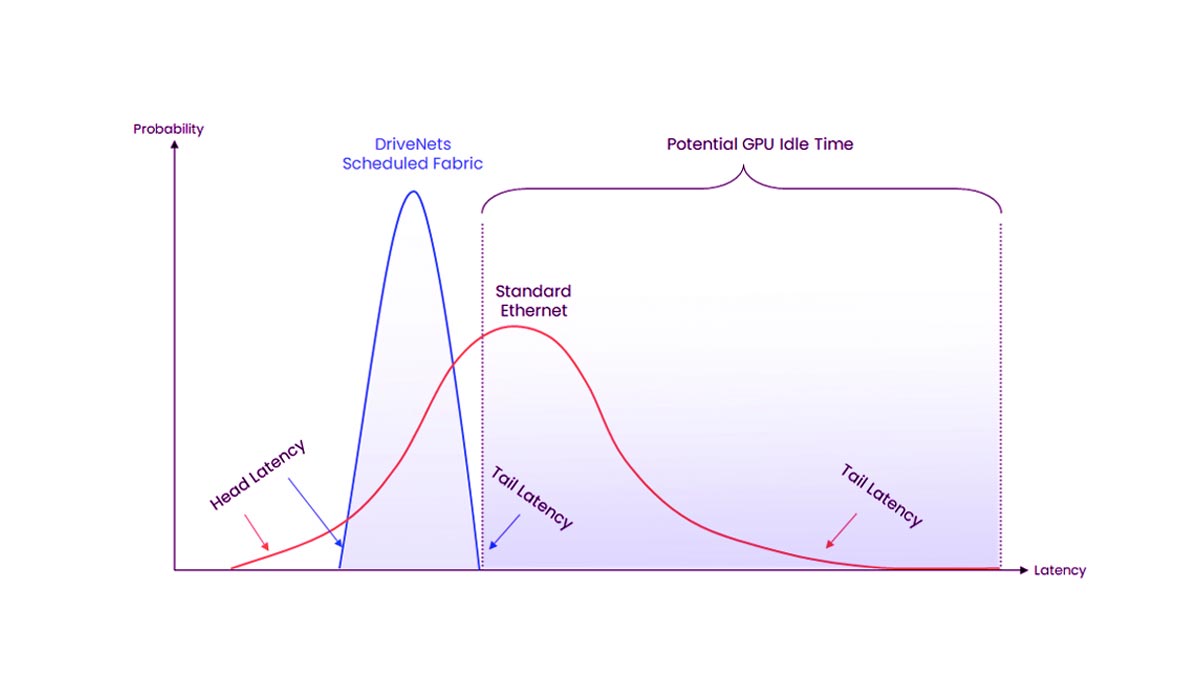
スパインリーフ型および非遮断型アーキテクチャ
ほとんどのAIクラスターは スパインリーフトポロジー なぜなら、GPUノード全体で予測可能な低遅延通信と拡張可能な帯域幅を提供するからです。
このアーキテクチャでは:
この設計はボトルネックを最小限に抑え、AIトレーニングでよく見られる高帯域幅の東西トラフィックパターンをサポートします。
大規模なAI導入は、多くの場合、 非ブロッキング生地ネットワークが十分な帯域幅を提供することで、All-ReduceやAll-GatherなどのGPU通信操作中にノード間の競合を回避できます。
過剰応募戦略
オーバーサブスクリプションは、利用可能なアップリンク帯域幅がサーバー側の総帯域幅よりも少ない場合に発生します。
AIトレーニングクラスタにおいては、分散型GPUワークロードがノード間の継続的なトラフィックを生成するため、オーバーサブスクリプションを低く抑えることが重要です。オーバーサブスクリプションが高すぎると、レイテンシが増加し、トレーニング効率が低下する可能性があります。
一般的なアプローチは次のとおりです。
-
大規模AIトレーニングクラスタ向け1対1非ブロッキング設計
-
中規模GPU展開におけるオーバーサブスクリプション率の低さ
-
推論重視環境におけるオーバーサブスクリプションの増加
理想的な比率は、ワークロードの種類、GPUの数、および予算の制約によって異なります。
輻輳制御とロスレスネットワーク
AIワークロードは、パケット損失やネットワーク輻輳に非常に敏感です。わずかなネットワーク障害でも、分散トレーニングの速度が低下し、GPUがアイドル状態になる可能性があります。
安定性を向上させるために、AIファブリックは一般的に以下の技術を使用しています。
-
RDMA対応トランスポート
-
優先フロー制御 (PFC)
-
明示的輻輳通知(ECN)
-
データセンターブリッジング(DCB)
これらの技術は、GPU通信において、より予測可能で低遅延な環境を構築するのに役立ちます。
InfiniBandは輻輳管理機能を内蔵している一方、イーサネットベースのRoCEv2では、ロスレス動作を維持するために慎重な調整が必要となる。
NCCL、RDMA、およびネットワークチューニング
アプリケーションレベルの最適化も、AIネットワークのパフォーマンスにとって不可欠です。
NVIDIA NCCL(NVIDIA Collective Communications Library)は、マルチGPU通信に広く利用されており、効率的なネットワーク伝送に大きく依存しています。適切なRDMA構成は、CPUオーバーヘッドを削減し、GPU間のデータ転送効率を向上させるのに役立ちます。
一般的な最適化領域は以下のとおりです。
-
NCCLトポロジーチューニング
-
RDMAキュー構成
-
GPUアフィニティとNUMAアライメント
-
MTU最適化
-
トラフィックパスバランシング
これらのネットワークおよびアプリケーションレベルの最適化を組み合わせることで、通信オーバーヘッドを削減し、分散型AIトレーニングのスケーラビリティを向上させることができます。
⭐ AIクラスタネットワークおよび光モジュール
光モジュールは、現代のAIクラスタネットワークの中核を成すコンポーネントです。GPUクラスタが数百から数千のアクセラレータへと規模を拡大するにつれ、ネットワークはサーバーやスイッチ間で極めて高い帯域幅、低遅延、そして信頼性の高い信号伝送を実現する必要があります。そのため、高速光インターコネクトはAIデータセンターにおいて不可欠なものとなっています。
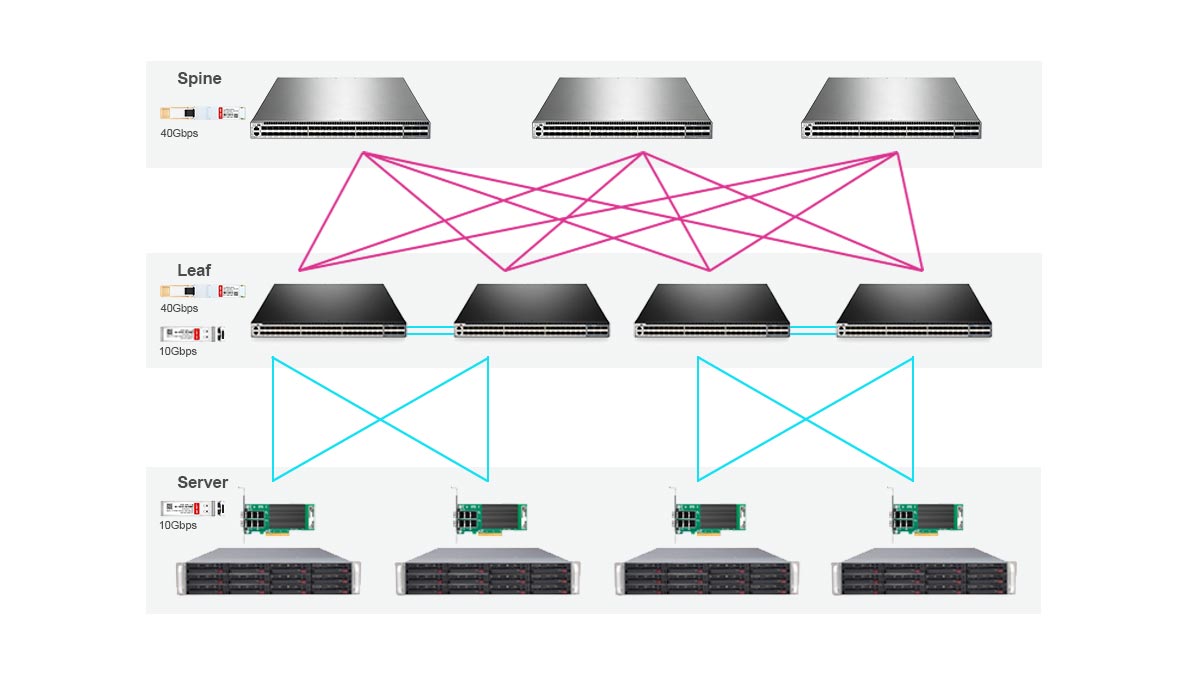
AIファブリックにおいて光モジュールが重要な理由
分散型AIトレーニングでは、GPUノード間で膨大な東西トラフィックが発生します。銅線ケーブルだけでは、大規模なAIクラスタ内部における長距離・高密度な400Gおよび800G接続を効率的にサポートすることはできません。
光モジュールは、いくつかの重要な課題の解決に役立ちます。
-
高帯域幅GPU通信
-
低遅延データ伝送
-
拡張可能な背葉構造の拡張
-
距離による信号劣化の低減
-
高密度ラックにおけるケーブル管理の改善
AIクラスターの規模が拡大し続けるにつれて、安定したパフォーマンスと高いGPU利用率を維持するために、光ネットワークの重要性がますます高まっている。
AIクラスターにおける100G、400G、800G光通信
現代のAIインフラストラクチャは、100Gネットワークから400Gおよび800Gファブリックへと急速に移行している。
1. 100G光通信
100Gトランシーバーは、小規模なGPUクラスター、ストレージネットワーク、および従来のAI環境では依然として広く使用されています。
一般的な使用例は次のとおりです:
-
小規模なAIトレーニングクラスター
-
推論ネットワーク
-
ストレージ相互接続
-
エッジAIの導入
2. 400G光通信
400Gは、分散型GPU通信において大幅に高い帯域幅を提供するため、多くの企業やハイパースケールAI導入において主流の選択肢となっている。
一般的な400G光モジュールには以下のようなものがあります。
-
QSFP-DDSR8 は、
-
QSFP-DD DR4
-
QSFP-DD FR4
これらのモジュールは、最新のAIファブリックにおけるスパイン・リーフ間およびリーフ・サーバー間の接続に広く使用されています。
3. 800G光通信
800Gネットワークは、超大規模モデルのトレーニングや高密度GPU展開向けに設計された次世代AIクラスターにおいて、注目を集めている。
800G OSFPおよびQSFP-DD800トランシーバーは、以下の機能を向上させます。
-
ネットワークスループット
-
ポート密度
-
ファブリックの拡張性
-
将来を見据えた能力
QSFP-DD、OSFP、およびブレークアウト接続
現在、AIネットワークは主に2つのフォームファクターで支配されています。
1. QSFP-DD
QSFP-DDモジュールは、高いポート密度と既存のイーサネットエコシステムとの高い互換性を提供するため、広く採用されている。
一般的には次のような用途に使用されます:
2. OSFP
OSFPモジュールは、より高い電力性能と熱性能を実現するように設計されており、800G AIファブリックにおいてますます普及が進んでいる。
OSFPは、以下のような場合によく好まれます。
-
ハイパースケールAIクラスター
-
高出力GPUネットワーク環境
-
超高密度スイッチプラットフォーム
3. ブレイクアウトオプション
ブレークアウト接続により、1つの高速ポートを複数の低速リンクに分割できます。例えば、以下のようなリンクです。
-
400Gから4×100G
-
800Gから2×400G
-
800Gから8×100G
ブレークアウト設計は柔軟性を向上させ、AIファブリックにおけるスイッチポートの利用効率を最適化するのに役立ちます。
AIクラスターリンク向け光学系の選択
光モジュールの選定は、リンク距離、帯域幅要件、消費電力、および展開トポロジーによって決まります。
1. スイッチ間リンク
背骨と葉の連結には通常、以下のものが必要です。
-
より高い帯域幅
-
より長いリーチ
-
大規模展開向けのシングルモードファイバー
これらのシナリオでは、400G DR4、FR4、および800Gの光ファイバーが一般的に使用されます。
2. サーバーへの切り替えリンク
リーフサーバーとGPUサーバー間の接続は通常より短く、以下のものを使用する場合があります。
最適な選択は、ラックの密度と熱設計によって異なります。
光ファイバー vs. DAC vs. AOC
|
テクノロジー
|
優位性
|
製品制限
|
典型的な使用例
|
|
ファイバー光学
|
長距離通信、高帯域幅、拡張性
|
より高いコスト
|
背表紙生地
|
|
DAC
|
低コスト、低消費電力
|
非常に短い距離
|
同一ラック接続
|
|
AOC
|
軽量で柔軟性があり、DACよりも長い距離をカバー
|
DACよりも高コスト
|
クロスラックGPUリンク
|
現代のAIクラスタネットワークでは、コスト、密度、電力効率、拡張性のバランスを取るために、大規模な展開のほとんどで光ファイバー、DAC、AOCが組み合わされています。
⭐ AIトレーニングと推論のための帯域幅計画
帯域幅計画は、AIクラスタのネットワーク設計において非常に重要な要素です。ネットワーク帯域幅が不足すると、GPUの利用率が低下し、トレーニング時間が長くなり、ネットワーク全体に輻輳によるボトルネックが発生する可能性があります。適切なネットワーク容量は、ワークロードの種類、クラスタのサイズ、および将来の拡張要件に大きく依存します。
ワークロードの種類が帯域幅需要に与える影響
AIのワークロードが異なると、生成されるトラフィックパターンも大きく異なる。
1. AIトレーニングのワークロード
分散型AIトレーニングでは、同期処理中にGPUが勾配、テンソル、モデルパラメータを絶えず交換するため、東西方向のトラフィックが非常に高くなります。
トレーニング環境では通常、以下のことが求められます。
-
超高スループット
-
低レイテンシ
-
RDMA対応通信
-
応募超過率が低い
大規模言語モデル(LLM)のトレーニングクラスタは、効率的なGPU同期を維持するために、400Gまたは800Gのファブリックに依存することが多い。
2. AI推論ワークロード
推論ワークロードは、ノード間の通信量が少ないため、通常は帯域幅の消費量が少なくなります。
推論ネットワークはしばしば以下の点を優先する。
-
速い応答時間
-
拡張性を要求します
-
コスト効率
-
柔軟な展開
多くの推論環境では、モデルのサイズとトラフィック量に応じて、100Gまたは400Gのイーサネットファブリックで十分です。
シングルノードスケーリングとマルチノードスケーリング
AIワークロードが複数のサーバーにまたがって規模を拡大するにつれて、帯域幅の必要量は大幅に増加する。
1. シングルノードAIシステム
シングルノードGPUサーバーは、主にNVLinkやPCIeなどの内部GPU相互接続に依存しており、外部ネットワークへの依存度を低減している。
これらの環境では、通常、ファブリック帯域幅は少なくて済みます。
2. マルチノードAIクラスタ
マルチノード構成では、GPUがサーバー間でデータを継続的に同期する必要があるため、ネットワークトラフィックが大幅に増加します。
クラスターサイズが大きくなるにつれて:
-
東西方向の交通量が急速に増加している
-
渋滞のリスクが高まる
-
低遅延ファブリックの重要性が高まる
-
光インターコネクトの需要が増加
大規模な分散型トレーニングクラスタでは、多くの場合、ノンブロッキング型の400Gまたは800Gスパインリーフアーキテクチャが必要となる。
現在および将来のAI成長に向けた計画
AIインフラの要件は急速に進化している。当初100Gネットワークを導入していた多くの組織は、現在400Gへのアップグレードを進め、800Gへの拡張性にも備えている。
AIファブリックを計画する際には、以下の点を考慮することが重要です。
-
将来のGPU拡張
-
モデルサイズの増加
-
ラック密度の向上
-
光モジュールのアップグレードパス
-
スイッチの電力と冷却能力
将来の拡張性を考慮して設計することで、後々の高額なネットワーク再設計を削減できる。
400Gおよび800G AI生地の実用的なサイズ決定ルール
要件はワークロードによって異なりますが、現代のAIネットワークではいくつかの実用的なガイドラインが一般的に用いられています。
1. 100Gネットワーク
こんな方へ:
-
小型GPUクラスター
-
推論環境
-
開発およびテストシステム
2. 400Gネットワーク
推奨:
-
中規模から大規模なAIトレーニングクラスター
-
マルチラックGPU展開
-
高性能RoCEv2ファブリック
-
現代的な背葉型建築
400Gは、多くの企業向けAIデータセンターにおいて主流の選択肢となっている。
3. 800Gネットワーク
最適:
-
ハイパースケールAIインフラストラクチャ
-
超大規模分散トレーニング
-
将来を見据えたGPUファブリック
-
高密度AIスイッチプラットフォーム
AIワークロードの拡大に伴い、800Gファブリックは拡張性、ポート密度、および長期的な帯域幅効率の向上に貢献します。
⭐ AIクラスタのネットワークに関する一般的な問題とその解決方法
適切に設計されたAIクラスタであっても、ネットワークの問題が発生すると、GPUの利用率が低下し、分散トレーニングの速度が低下する可能性があります。AIワークロードはレイテンシとネットワークの混雑に非常に敏感であるため、小さなネットワークの問題でもクラスタ全体のパフォーマンスに急速に影響を与える可能性があります。

以下に、AIクラスタのネットワークにおける最も一般的な問題点とその実践的な解決策をいくつか紹介します。
レイテンシースパイク
予期せぬレイテンシーの急増は、GPUの同期を妨げ、All-Reduceなどの集合的な通信処理を遅くする可能性があります。
一般的な原因は次のとおりです。
-
ネットワークの過剰利用
-
密集した脊椎葉連結
-
不適切なQoSポリシー
-
高いCPU割り込み負荷
-
交通量の分布が不均一
遅延スパイクを軽減するには:
効率的な分散型AIトレーニングを維持するには、一貫して低遅延であることが不可欠です。
パケット損失と輻輳
パケット損失は、AIトレーニング環境において特に有害である。なぜなら、再送信によって数千ものGPU間での同期が遅延する可能性があるからだ。
渋滞はしばしば以下の原因によって引き起こされます。
-
東西方向の交通量が非常に多い
-
アップリンク帯域幅が不十分
-
列管理が不十分
-
集団運用中のトラフィックの急増
一般的な解決策は次のとおりです。
-
ロスレスイーサネット技術の導入
-
PFCとECNを正しく設定する
-
ファブリック帯域幅の増加
-
応募超過率の低減
-
インテリジェントな混雑制御メカニズムを使用する
InfiniBandファブリックは通常、輻輳管理機能を内蔵していますが、RoCEv2環境ではより慎重な調整が必要です。
RDMAまたはRoCEの設定ミス
RDMAの設定ミスは、AIネットワークのパフォーマンスが不安定になる最も一般的な原因の一つです。
典型的な問題は次のとおりです:
-
MTU設定が正しくありません
-
PFCの設定ミス
-
DCB構成が不適切
-
RDMAキューの不均衡
-
互換性のないスイッチ設定
症状としては、
-
GPU通信の不安定性
-
NCCLパフォーマンスが低い
-
予期せぬパケット損失
-
分散トレーニング中の高遅延
RDMAの安定性を向上させるには:
-
クラスター全体でネットワーク構成を標準化する
-
PFCとECNの行動を検証する
-
一貫したMTU設定を使用する
-
RDMAのパフォーマンスを定期的にテストする
-
NCCLの通信効率を監視する
ドライバーとファームウェアの不一致の問題
AIクラスタは、NIC、スイッチ、GPU、およびオペレーティングシステム間の互換性に大きく依存します。ファームウェアの不一致は、予測不能なパフォーマンス問題やRDMA障害を引き起こす可能性があります。
一般的な問題領域は次のとおりです。
-
NICファームウェアの不整合
-
Switchソフトウェアの非互換性
-
GPUドライバの不一致
-
サポートされていないRDMA機能バージョン
ベストプラクティスは次のとおりです。
安定した大規模AI運用には、一貫したファームウェア管理が不可欠です。
クラスター全体でリンク利用率が低い
一部のAIクラスターでは、帯域幅の使用状況に偏りが見られ、特定のリンクが混雑する一方で、他のリンクは十分に活用されないままとなる。
これは多くの場合、以下の原因によって引き起こされます。
-
非効率的なECMPハッシュ
-
トポロジー設計が不十分
-
交通渋滞の激しい場所
-
GPU通信経路のバランスが崩れている
生地の利用効率を向上させるために:
-
脊椎葉構造のトポロジー設計を最適化する
-
ECMPポリシーの調整
-
スイッチ間でトラフィックパスのバランスを取る
-
流量分布を継続的に監視する
-
テレメトリおよびファブリック分析ツールを使用する
効率的なリンク利用は、利用可能な帯域幅を最大限に活用し、AIトレーニングの全体的な拡張性を向上させるのに役立ちます。
⭐ AIクラスタネットワークに関するよくある質問

Q1:AIクラスターにとって最適なネットワークは何ですか?
AIクラスタに最適なネットワークは、ワークロードの規模、レイテンシ要件、および予算によって異なります。大規模な分散型AIトレーニング環境では、超低レイテンシと強力なRDMA性能を持つInfiniBandがよく使用されます。エンタープライズAIの導入においては、拡張性、コスト、および運用上の柔軟性のバランスを考慮して、イーサネットよりもRoCEv2が一般的に選択されます。
Q2:InfiniBandはRoCEv2よりも優れていますか?
InfiniBandは一般的に、ハイパースケールAIトレーニングクラスタにおいて、低遅延とより高度な輻輳管理を実現します。しかし、RoCEv2はRDMA性能と標準イーサネットインフラストラクチャを組み合わせることで、導入コストを削減し、エンタープライズネットワークとの互換性を向上させるため、人気の代替手段となっています。
多くの組織にとって、RoCEv2はパフォーマンスと拡張性の最適なバランスを提供します。
Q3:AIクラスターには400Gまたは800Gの光ファイバーが必要ですか?
最新のAIトレーニングクラスタでは、高帯域幅のGPU通信をサポートするために、400Gおよび800Gの光モジュールへの依存度が高まっている。
小規模な推論クラスタや開発環境であれば、100Gネットワークでも効率的に動作する可能性があります。
Q4:イーサネットはAIトレーニングに対応できますか?
はい。最新のイーサネットファブリックとRoCEv2およびRDMA技術を組み合わせることで、大規模なAIトレーニングを効果的にサポートできます。現在、多くの企業AIデータセンターでは、分散型GPUワークロード向けに、ロスレスネットワーク構成を備えた高速イーサネットを使用しています。
しかし、イーサネットベースのAIファブリックでは、以下のような技術の慎重な調整が必要です。
-
PFC(優先フロー制御)
-
ECN(明示的輻輳通知)
-
DCB(データセンターブリッジング)
適切な設定が行われていない場合、輻輳やパケット損失によってトレーニング効率が低下する可能性があります。
Q5:光モジュールはAIクラスタのパフォーマンスにどのような影響を与えますか?
光モジュールは、AIクラスタネットワークにおける帯域幅、遅延、拡張性、および信号の信頼性に直接影響を与える。
QSFP-DDやOSFPモジュールなどの高速トランシーバーは、以下のことを可能にします。
-
400Gおよび800G接続
-
長距離の棘葉間コミュニケーション
-
高密度GPUファブリック
-
信号劣化の低減
-
分散型AIワークロードの拡張性の向上
スイッチ間およびスイッチとサーバー間のリンクに適切な光学系を選択することで、AIクラスタ全体のパフォーマンスと将来的な拡張性を向上させることができます。
⭐ 将来のAIネットワークプロジェクトのためのベストプラクティス
AIインフラストラクチャがより大規模なGPUクラスタと400G/800Gファブリックへと移行し続ける中、今日のネットワーク設計上の決定は、長期的な拡張性、運用安定性、および導入コストに直接影響を与えます。成功するAIクラスタネットワークプロジェクトは、もはや帯域幅だけに着目するのではなく、可観測性、相互運用性、そして将来の光拡張性も優先的に考慮する必要があります。

可観測性を最優先に構築する
AIクラスターは膨大な量の東西トラフィックを生成するため、可視性と監視が不可欠です。最新のAIファブリックには以下が含まれるべきです。
-
リアルタイムテレメトリ
-
混雑状況の監視
-
RDMAパフォーマンス分析
-
GPU通信の可視性
-
スイッチおよび光診断
早期に状況を把握することで、ボトルネックがGPUの利用率やトレーニング効率に影響を与える前に特定することができます。
デザインはベンダーニュートラルに保つ
ベンダーロックインは、将来的な拡張性を制限し、インフラコストを増加させる可能性があります。可能な限り、組織はオープンなイーサネット規格、相互運用可能な光通信技術、および柔軟なスパインリーフアーキテクチャに基づいてAIファブリックを設計すべきです。
ベンダーニュートラルな戦略は、以下の点を改善します。
-
ハードウェアの柔軟性
-
アップグレードオプション
-
長期的なコスト管理
-
マルチベンダー互換性
ファームウェアとケーブルの標準化
ファームウェアの不整合は、AIネットワークの不安定化の最も一般的な原因の一つです。NICファームウェア、スイッチソフトウェア、光モジュール、ケーブルの種類を標準化することで、予期せぬ相互運用性の問題を軽減できます。
ベストプラクティスは次のとおりです。
-
ファームウェアのバージョンを一定に保つ
-
検証済みの光学互換性リストを使用する
-
DAC、AOC、および光ファイバー展開の標準化
-
本番環境への展開前にアップグレードをテストする
文書トポロジーとチューニングパラメータ
大規模なAIファブリックは非常に複雑になる可能性があります。適切なドキュメントを作成することで、トラブルシューティングや将来の拡張が容易になります。
記録しておくべき重要な項目は以下のとおりです。
-
背葉トポロジー設計
-
RDMAとRoCEの設定
-
ECMPポリシー
-
応募超過率
-
光モジュール展開計画
-
NCCLチューニングパラメータ
十分に文書化された環境は、時間の経過とともに拡張や保守が容易になります。
スイッチポートだけでなく、光スケーリングも計画しましょう
将来のAIの発展には、スイッチポートの増設だけでは到底足りません。光帯域幅密度、電力効率、ケーブル管理といった要素も、同様に重要な設計要素になりつつあります。
新しいAIインフラストラクチャを導入する組織は、すでに以下の準備を進めておくべきです。
-
400Gから800Gへの移行パス
-
ラック密度の向上
-
OSFPおよびQSFP-DD800の採用
-
拡張可能な光ファイバーインフラストラクチャ
-
将来の超クラスターアーキテクチャ
適切な光エコシステムを早期に選択することで、将来のアップグレードの複雑さを大幅に軽減できます。
AI クラスタ ネットワークが進化し続けるにつれて、高品質の光インターコネクトと信頼性の高いイーサネット コンポーネントは、スケーラブルな GPU インフラストラクチャの基盤であり続けるでしょう。最新の AI ファブリックを計画している組織にとって、 LINK-PP オフィシャルストア エンタープライズAI、HPC、データセンターの導入向けに設計された、幅広い高速光モジュール、DAC/AOCソリューション、およびネットワーク接続製品を提供しています。
































