

























Live-Chat
Wir sind rund um die Uhr für Sie da.
Schreiben Sie uns jetzt, um schnell eine Antwort zu erhalten.
Alle Kategorien
SFP-Module
Leistungen
Unterstützung
Über uns
Ressourcen


Kümmern Sie sich um Ihr Geschäft mit einer Vielzahl vertrauenswürdiger Zahlungsoptionen.
Verwenden Sie die Bestellnummer oder die Sendungsverfolgungsnummer, um den Versandstatus zu überprüfen.
Erhalten Sie schnell Ihr Angebot und profitieren Sie von einem professionelleren Service.
Helfen Sie dabei, Ihr Budget und Ihre Ausgaben besser zu verwalten.
Kostenlose Probenunterstützung, um Ihre Testergebnisse effizient zu erzielen.
Professionelle Teamunterstützung und Service, um Ihre Probleme rechtzeitig zu lösen.
Fragen Sie uns, was immer Sie interessiert, wir helfen Ihnen rund um die Uhr.
Erhalten Sie schnell Ihr Angebot und bieten Sie einen professionelleren Service.
Lernen Sie uns kennen und erfahren Sie mehr über unsere Mission, unseren Glauben, unseren Service und mehr.
Finden Sie unsere Standorte und vernetzen Sie sich intensiv mit uns.
Entdecken Sie, wie uns die Qualität am Herzen liegt.
Erfahren Sie die neuesten Nachrichten und Veranstaltungen in der Umgebung l-p.com
Tiefgehende Einblicke in technische Leitfäden, Industriestandards und SFP-Kompatibilität.
Detaillierte Produkt-Benchmarks und direkte Vergleiche helfen Ihnen bei der Auswahl des richtigen Moduls.
Entdecken Sie praxisnahe Konnektivitätslösungen für Rechenzentren, Unternehmen und Telekommunikationsnetze.
Wichtige Tipps zur Auswahl von Datenraten, Übertragungsdistanzen und Steckertypen.





Mit zunehmender Skalierung von KI-Modellen ist die Netzwerkleistung ebenso wichtig geworden wie die GPU-Performance. Moderne KI-Workloads basieren auf verteilten GPU-Clustern, die während des Trainings und der Inferenz massiven Ost-West-Datenverkehr erzeugen. Daher ist eine Netzwerkarchitektur mit geringer Latenz und hoher Bandbreite für die Gesamteffizienz des Systems unerlässlich.
Das ist wo KI-Cluster-Netzwerk spielt eine entscheidende Rolle.
KI-Cluster-Netzwerke bezeichnen die Hochleistungsnetzwerkinfrastruktur, die GPU-Server, Speichersysteme und KI-Beschleuniger in KI-Rechenzentren und HPC-Umgebungen verbindet. Im Gegensatz zu herkömmlichen Unternehmensnetzwerken benötigen KI-Cluster ultraschnelle Kommunikation zwischen den Knoten, um verteilte Rechenframeworks wie NCCL und RDMA-basierte GPU-Kommunikation zu unterstützen.
Um Engpässe zu reduzieren und die GPU-Auslastung zu maximieren, verwenden moderne KI-Architekturen üblicherweise Technologien wie:
InfiniBand
RoCEv2 und RDMA
Verlustfreie Ethernet-Fabrics
Spine-Leaf-Netzwerkarchitekturen
400G- und 800G-optische Verbindungen
Auf der physikalischen Schicht sind optische Module zu einem Schlüsselelement im Design von KI-Infrastrukturen geworden. Hochgeschwindigkeits-Transceiver wie QSFP-DD- und OSFP-Module ermöglichen skalierbare 400G- und 800G-Konnektivität zwischen Switches und GPU-Servern bei gleichzeitig geringer Latenz und hoher Portdichte.
In diesem Leitfaden erklären wir die Funktionsweise von KI-Cluster-Netzwerken, vergleichen die Architekturen von InfiniBand und RoCEv2, untersuchen RDMA- und Staukontrolltechnologien und erforschen, wie optische Module die Skalierbarkeit moderner KI-Cluster im Jahr 2025 und darüber hinaus unterstützen.
KI-Cluster-Netzwerke bezeichnen die Hochleistungsnetzwerkarchitektur, die GPU-Server, KI-Beschleuniger, Speichersysteme und Switches in KI-Rechenzentren und HPC-Umgebungen (High-Performance Computing) verbindet. Ihr Hauptzweck ist der extrem schnelle Datenaustausch zwischen den Rechenknoten bei verteilten KI-Workloads.
In der praktischen Anwendung im Ingenieurwesen dient die Vernetzung von KI-Clustern der Lösung eines zentralen Problems: der optimalen Auslastung von GPUs bei umfangreichen Trainings- und Inferenzaufgaben. Da moderne KI-Modelle zu groß sind, um effizient auf einer einzelnen GPU oder gar einem einzelnen Server ausgeführt zu werden, werden die Arbeitslasten auf mehrere Knoten verteilt, die ihre Daten ständig synchronisieren müssen. Das Netzwerk wird somit Teil des Rechensystems selbst und nicht nur eine Transportschicht.
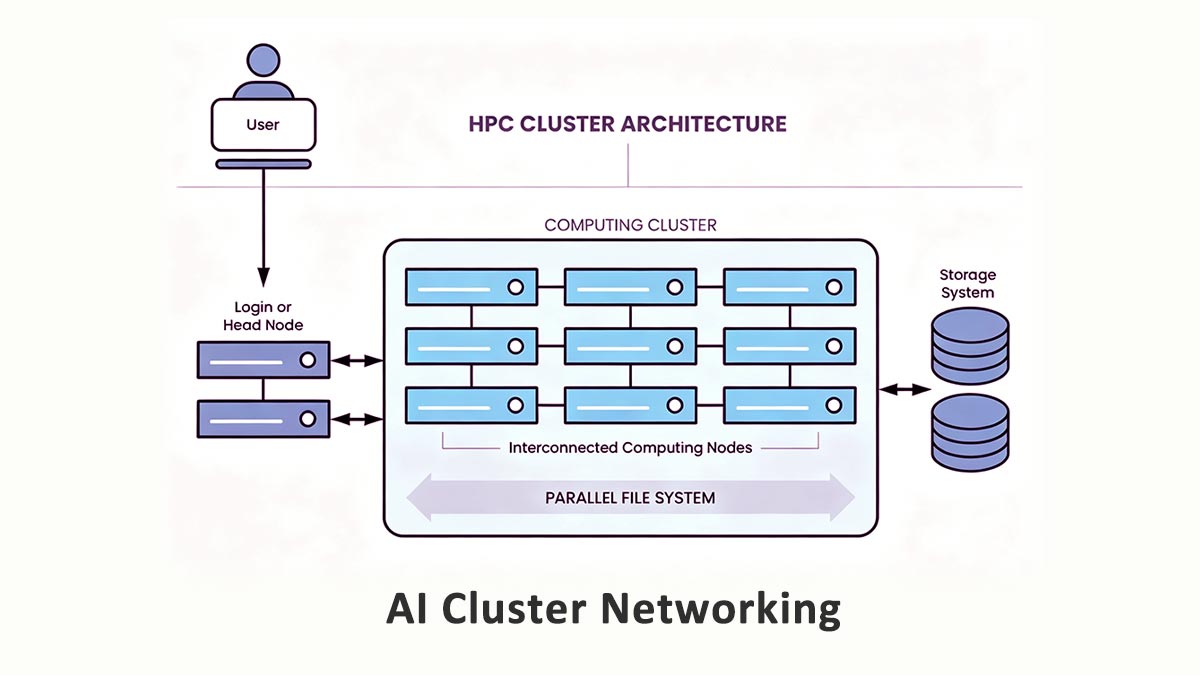
Im Gegensatz zu herkömmlichen Unternehmensnetzwerken, die hauptsächlich die Kommunikation zwischen Benutzer und Server abwickeln, erzeugen KI-Cluster massive Datenmengen. Ost-West-Verkehr — Daten, die innerhalb des Rechenzentrums seitlich zwischen GPUs, Servern und Speichersystemen übertragen werden.
Für das Training verteilter KI-Systeme ist ein kontinuierlicher Austausch von Gradienten, Tensoren, Modellparametern und Synchronisationsdaten zwischen GPUs erforderlich. Bei Operationen wie Datenparallelität, Tensorparallelität und Pipeline-Parallelität kann jede GPU gleichzeitig mit vielen anderen GPUs kommunizieren.
Dadurch entstehen extrem bandbreitenintensive Ost-West-Verkehrsmuster.
Beispielsweise führen GPUs während des Trainings großer Sprachmodelle (LLM) häufig kollektive Kommunikationsoperationen durch, wie etwa:
All-Reduce
Alle-Gather
Broadcast
Streuung reduzieren
Diese Operationen erzeugen einen hohen Datenverkehr zwischen den Knoten, der sehr empfindlich auf Folgendes reagiert:
Latency
Paketverlust
Stau
Jitter
Netzwerküberbelegung
Selbst geringfügige Verzögerungen bei der Synchronisierung können dazu führen, dass teure GPUs ungenutzt bleiben, was die Clustereffizienz erheblich verringert und die Trainingszeit verlängert.
Aus diesem Grund werden in KI-Netzwerkumgebungen üblicherweise folgende Elemente eingesetzt:
Nicht blockierende Dorn-Blatt-Topologien
RDMA-fähige Textilien
Verlustfreies Ethernet oder InfiniBand
400G- und 800G-optische Verbindungen
Intelligente Mechanismen zur Staukontrolle
Ziel ist es, den Kommunikationsaufwand zu minimieren und eine vorhersehbare Leistung mit niedriger Latenz im gesamten Cluster aufrechtzuerhalten.
Obwohl sowohl das Training als auch die Inferenz von KI auf Hochgeschwindigkeitsnetzwerke angewiesen sind, unterscheiden sich ihre Datenverkehrsmuster und Infrastrukturanforderungen stark.
KI-Trainingsumgebungen priorisieren:
Extrem niedrige Latenz
hoher Durchsatz
GPU-Synchronisierungseffizienz
Große Ost-West-Bandbreitenkapazität
RDMA und Optimierung der kollektiven Kommunikation
Trainingscluster nutzen häufig InfiniBand- oder RoCEv2-Fabrics mit 400G/800G-Optikmodulen, um eine kontinuierliche GPU-zu-GPU-Kommunikation in großem Umfang zu unterstützen.
Bei Inferenz-Workloads liegt der Fokus üblicherweise stärker auf Folgendem:
Schnelle Antwortzeit
Skalierbarkeit für Benutzeranfragen
Nord-Süd-Verkehrsabwicklung
Kosteneffizienz
Lastverteilung
Inferenzcluster benötigen möglicherweise nicht dieselbe extrem niedrige Latenz wie Trainingsumgebungen, insbesondere bei Inferenz-Workloads auf Einzelknoten oder mit geringer Verteilung. In vielen Fällen sind Hochgeschwindigkeits-Ethernet-Netzwerke ausreichend.
Da jedoch groß angelegte verteilte Inferenz- und Echtzeit-KI-Anwendungen immer weiter zunehmen, werden auch die Anforderungen an die Inferenznetzwerke immer anspruchsvoller, insbesondere für KI-Architekturen mit mehreren Knoten.
Die Wahl der richtigen Netzwerkarchitektur für KI-Cluster hat direkten Einfluss auf GPU-Auslastung, Latenz, Skalierbarkeit und Bereitstellungskosten. Aktuell basieren die meisten KI-Infrastrukturen auf drei Hauptansätzen: InfiniBand, RoCEv2 und Standard-Ethernet.
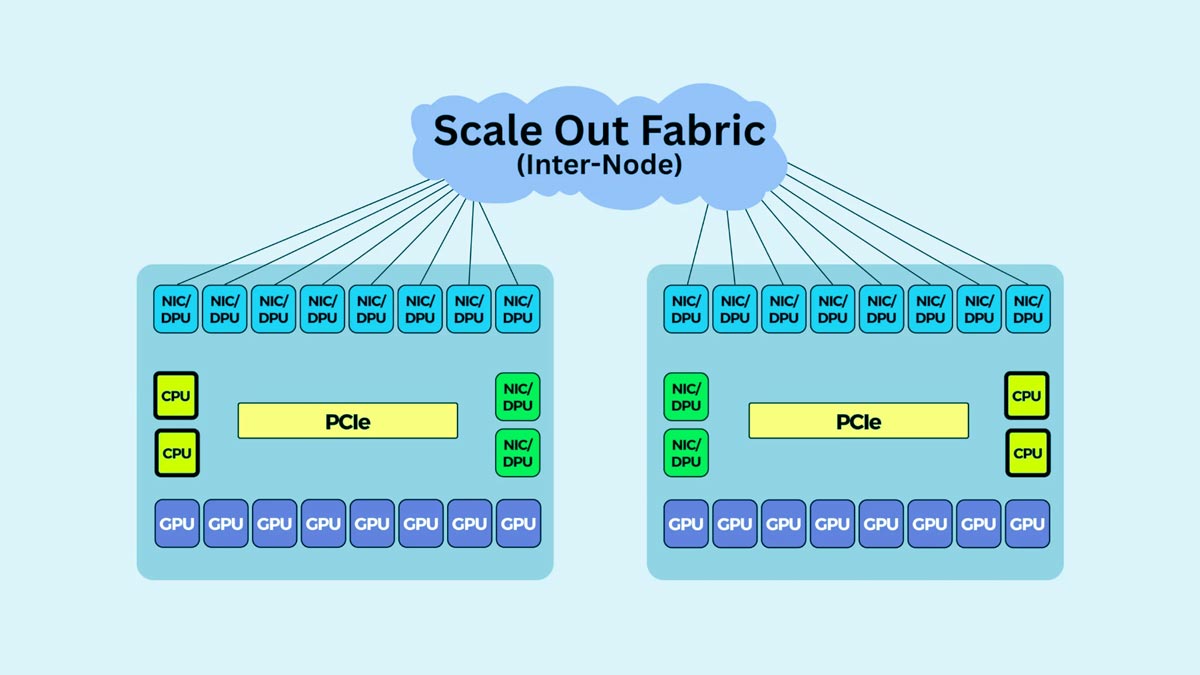
InfiniBand wird aufgrund seiner extrem niedrigen Latenz, des hohen Durchsatzes und der fortschrittlichen Staukontrolle häufig in Hyperscale-KI-Trainings- und HPC-Umgebungen eingesetzt. Es ist für RDMA und großflächige GPU-Kommunikation optimiert und eignet sich daher ideal für verteilte KI-Trainings-Workloads.
Zu den wichtigsten Vorteilen gehören:
Extrem niedrige Latenz
Hohe GPU-Kommunikationseffizienz
Starke RDMA-Leistung
Hervorragende Skalierbarkeit für große Cluster
InfiniBand ist jedoch auch mit höheren Kosten und einer größeren Implementierungskomplexität verbunden, weshalb es sich am besten für Folgendes eignet:
Große KI-Trainingscluster
HPC-Umgebungen
Multi-Rack-GPU-Bereitstellungen
RoCEv2 (RDMA over Converged Ethernet) erweitert Ethernet-Netzwerke um RDMA-Funktionen. Es bietet ein optimales Verhältnis von Leistung, Skalierbarkeit und Kosten und lässt sich gleichzeitig einfacher in die Unternehmensinfrastruktur integrieren.
Zu den Vorteilen von RoCEv2 gehören:
Geringere Kosten als InfiniBand
Hochgeschwindigkeits-Ethernet-Kompatibilität
Gute Skalierbarkeit für KI-Workloads
Einfachere Unternehmensintegration
Um eine stabile Performance zu erzielen, benötigt RoCEv2 eine korrekte Konfiguration verlustfreier Ethernet-Technologien wie PFC und ECN.
RoCEv2 wird häufig verwendet in:
KI-Cluster für Unternehmen
Cloud-KI-Infrastruktur
Mittelgroße bis große GPU-Umgebungen
Standard-Ethernet bleibt eine praktikable Option für kleinere KI-Implementierungen und Inferenzcluster, bei denen eine GPU-Synchronisierung mit extrem niedriger Latenz weniger wichtig ist.
Vorteile sind:
Geringere Bereitstellungskosten
vereinfachtes Management
Breite Kompatibilität
Flexible Skalierung
Moderne 100G- und 400G-Ethernet-Netzwerke können viele KI-Inferenz-Workloads effektiv unterstützen, auch wenn sie für groß angelegte verteilte Trainingsanwendungen möglicherweise nicht mit RDMA-basierten Netzwerken mithalten können.
|
Funktion |
InfiniBand |
RoCEv2 |
Ethernet |
|---|---|---|---|
|
Latency |
Unterste |
Sehr geringe |
Moderat |
|
RDMA-Unterstützung |
Ureinwohner |
Unterstützt |
Begrenzt |
|
Kosten |
Höchste |
Medium |
Unterste |
|
Komplexität |
Hoch |
Medium |
Niedrig |
|
Bester Anwendungsfall |
Großes KI-Training |
KI-Cluster für Unternehmen |
Inferenz und kleinere Bereitstellungen |
Im Allgemeinen bleibt InfiniBand die beste Wahl für maximale KI-Trainingsleistung, RoCEv2 bietet das beste Verhältnis von Kosten und Skalierbarkeit, und Standard-Ethernet ist oft ausreichend für inferenzorientierte KI-Umgebungen.
Die Entwicklung einer KI-Infrastruktur mit geringer Latenz ist entscheidend für eine hohe GPU-Auslastung und effizientes verteiltes Training. In modernen KI-Clustern muss das Netzwerk massiven Ost-West-Datenverkehr mit minimaler Überlastung, minimalem Paketverlust und minimaler Synchronisationsverzögerung unterstützen.
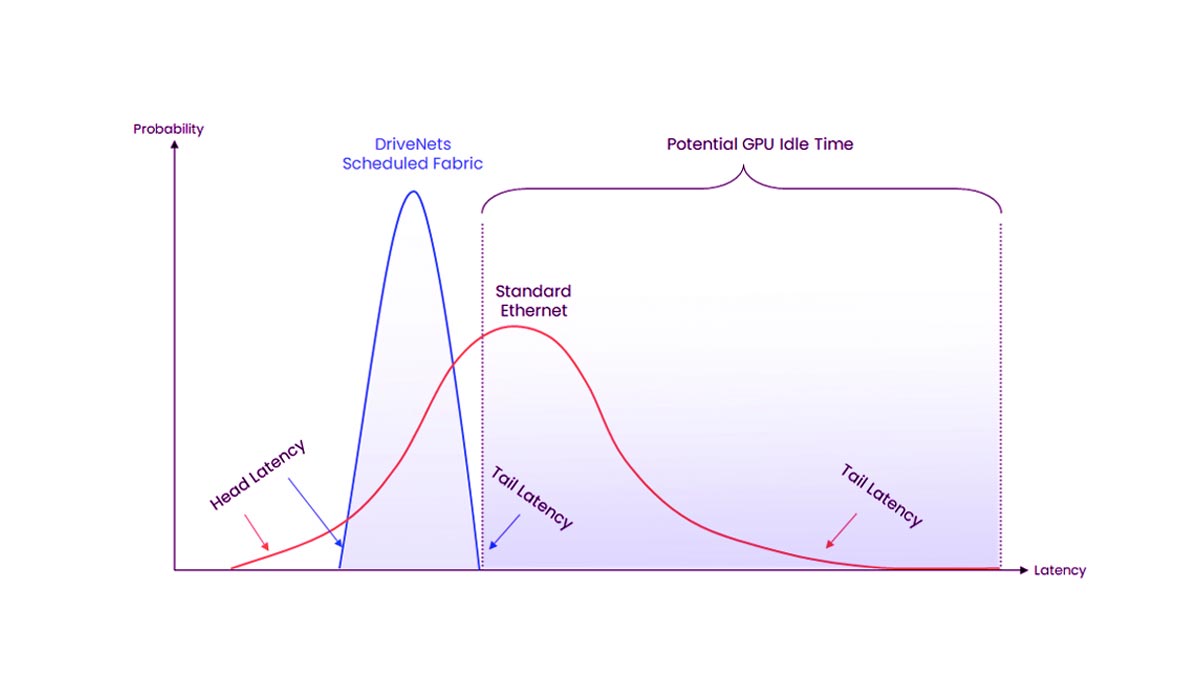
Die meisten KI-Cluster verwenden ein Spine-Leaf-Topologie weil es eine vorhersehbare Kommunikation mit niedriger Latenz und skalierbare Bandbreite über GPU-Knoten hinweg ermöglicht.
In dieser Architektur:
Leaf-Switches sind direkt mit GPU-Servern verbunden.
Spine-Switches verbinden alle Leaf-Switches.
Jeder Blattschalter hat gleichwertige Pfade zu anderen Blättern.
Dieses Design minimiert Engpässe und unterstützt die in KI-Trainingssystemen üblichen Ost-West-Verkehrsmuster mit hoher Bandbreite.
Große KI-Implementierungen zielen oft auf Folgendes ab: nicht blockierender Stoff, wobei das Netzwerk über genügend Bandbreite verfügt, um Konflikte zwischen den Knoten während GPU-Kommunikationsoperationen wie All-Reduce und All-Gather zu vermeiden.
Eine Überbuchung liegt vor, wenn die verfügbare Uplink-Bandbreite geringer ist als die gesamte serverseitige Bandbreite.
Für KI-Trainingscluster ist eine geringe Überbelegung wichtig, da verteilte GPU-Workloads kontinuierlichen Datenverkehr zwischen den Knoten erzeugen. Eine hohe Überbelegung kann die Latenz erhöhen und die Trainingseffizienz verringern.
Zu den gängigen Ansätzen gehören:
1:1-nicht-blockierende Designs für große KI-Trainingscluster
Niedrige Überbuchungsquoten bei mittleren GPU-Implementierungen
Höhere Überbelegung für inferenzorientierte Umgebungen
Das ideale Verhältnis hängt von der Art der Arbeitslast, der Anzahl der GPUs und den Budgetbeschränkungen ab.
KI-Workloads reagieren äußerst empfindlich auf Paketverluste und Netzwerküberlastung. Selbst geringfügige Netzwerkstörungen können das verteilte Training verlangsamen und GPUs ungenutzt lassen.
Zur Verbesserung der Stabilität verwenden KI-Gewebe üblicherweise Folgendes:
RDMA-fähiger Transport
Prioritätsstromregelung (PFC)
Explizite Überlastungsmeldung (ECN)
Rechenzentrumsüberbrückung (DCB)
Diese Technologien tragen dazu bei, eine besser vorhersagbare Umgebung mit geringer Latenz für die GPU-Kommunikation zu schaffen.
InfiniBand bietet ein integriertes Stau-Management, während Ethernet-basierte RoCEv2-Implementierungen eine sorgfältige Abstimmung erfordern, um einen verlustfreien Betrieb zu gewährleisten.
Eine Optimierung auf Anwendungsebene ist auch für die Leistungsfähigkeit von KI-Netzwerken unerlässlich.
NVIDIA NCCL (NVIDIA Collective Communications Library) wird häufig für die Multi-GPU-Kommunikation eingesetzt und ist stark von einem effizienten Netzwerktransport abhängig. Eine korrekte RDMA-Konfiguration trägt dazu bei, den CPU-Overhead zu reduzieren und die Effizienz der GPU-zu-GPU-Datenübertragung zu verbessern.
Gängige Optimierungsbereiche sind:
NCCL-Topologieoptimierung
RDMA-Warteschlangenkonfiguration
GPU-Affinität und NUMA-Ausrichtung
MTU-Optimierung
Verkehrsflussausgleich
Zusammengenommen tragen diese Optimierungen auf Netzwerk- und Anwendungsebene dazu bei, den Kommunikationsaufwand zu reduzieren und die Skalierbarkeit des verteilten KI-Trainings zu verbessern.
Optische Module sind eine Kernkomponente moderner KI-Cluster-Netzwerke. Mit der Skalierung von GPU-Clustern von Hunderten auf Tausende von Beschleunigern muss das Netzwerk extrem hohe Bandbreite, geringe Latenz und zuverlässige Signalintegrität zwischen Servern und Switches gewährleisten. Daher sind optische Hochgeschwindigkeitsverbindungen in KI-Rechenzentren unerlässlich.
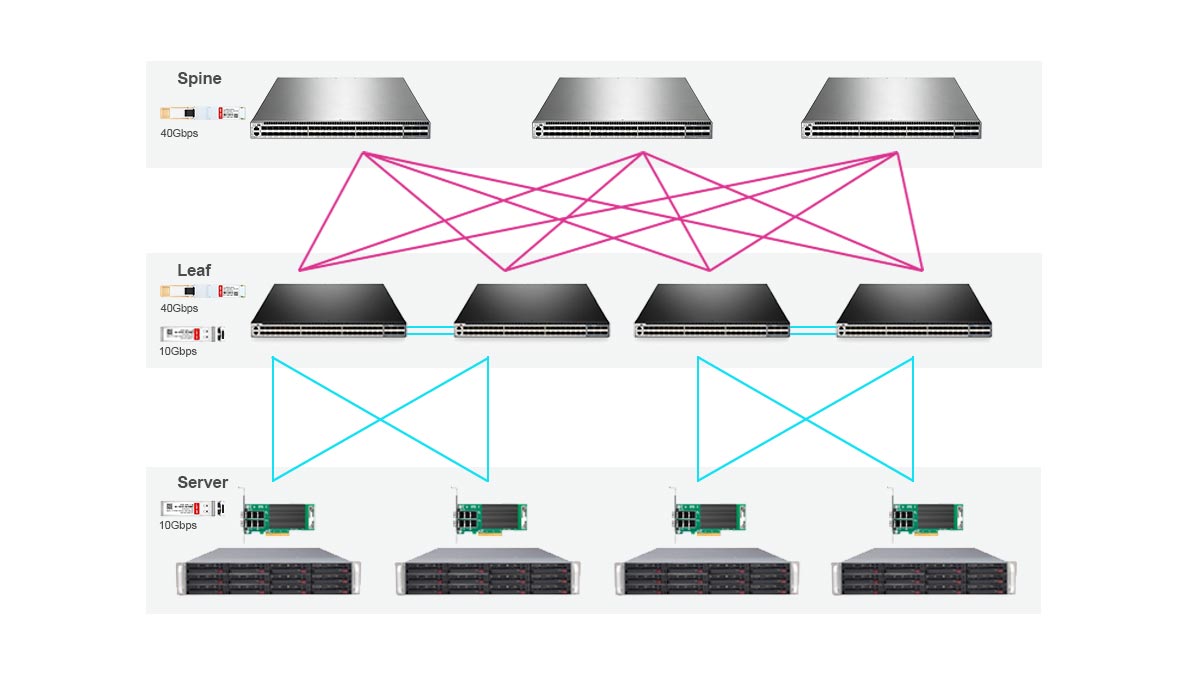
Das Training verteilter KI-Systeme erzeugt einen massiven Ost-West-Datenverkehr zwischen den GPU-Knoten. Kupferkabel allein können die weitreichende und hochdichte 400G- und 800G-Konnektivität innerhalb großer KI-Cluster nicht effizient unterstützen.
Optische Module helfen dabei, mehrere kritische Herausforderungen zu bewältigen:
GPU-Kommunikation mit hoher Bandbreite
Datenübertragung mit geringer Latenz
Skalierbare Erweiterung des Wirbelsäulen-Blatt-Gewebes
Verringerte Signalverschlechterung über die Entfernung
Verbessertes Kabelmanagement in dicht bestückten Racks
Da KI-Cluster immer weiter wachsen, gewinnt die optische Netzwerktechnik zunehmend an Bedeutung für die Aufrechterhaltung einer stabilen Leistung und einer hohen GPU-Auslastung.
Moderne KI-Infrastrukturen vollziehen einen rasanten Übergang von 100G-Netzen hin zu 400G- und 800G-Architekturen.
100G-Transceiver sind in kleineren GPU-Clustern, Speichernetzwerken und älteren KI-Umgebungen immer noch weit verbreitet.
Typische Anwendungsfälle sind:
Kleine KI-Trainingscluster
Inferenznetzwerke
Speicherverbindungen
Edge-KI-Bereitstellungen
400G hat sich bei vielen KI-Implementierungen in Unternehmen und Hyperscale-Umgebungen zur Standardwahl entwickelt, da es eine deutlich höhere Bandbreite für die verteilte GPU-Kommunikation bietet.
Gängige optische 400G-Module sind:
QSFP-DD SR8
QSFP-DD DR4
QSFP-DD FR4
Diese Module werden in modernen KI-Architekturen häufig für die Spine-to-Leaf- und Leaf-to-Server-Konnektivität eingesetzt.
800G-Netzwerke etablieren sich in KI-Clustern der nächsten Generation, die für das Training extrem großer Modelle und den Einsatz von GPUs mit hoher Dichte konzipiert sind.
800G OSFP- und QSFP-DD800-Transceiver tragen zur Steigerung bei:
Netzwerkdurchsatz
Portdichte
Gewebeskalierbarkeit
Zukunftssicherheit
Zwei Hauptformfaktoren dominieren heute die KI-Netzwerke:
QSFP-DD-Module sind weit verbreitet, da sie eine hohe Portdichte und eine starke Kompatibilität mit bestehenden Ethernet-Ökosystemen bieten.
Sie werden häufig verwendet für:
100G
200G
400G
800G-Bereitstellungen
OSFP-Module sind auf höhere Leistungs- und Wärmeleistung ausgelegt und erfreuen sich daher zunehmender Beliebtheit in 800G-KI-Architekturen.
OSFP wird oft bevorzugt in:
Hyperscale KI-Cluster
Hochleistungsfähige GPU-Netzwerkumgebungen
Switch-Plattformen mit ultrahoher Dichte
Breakout-Konnektivität ermöglicht es, einen Hochgeschwindigkeitsport in mehrere Verbindungen mit niedrigerer Geschwindigkeit aufzuteilen, wie zum Beispiel:
400G bis 4×100G
800G bis 2×400G
800G bis 8×100G
Breakout-Designs verbessern die Flexibilität und tragen zur Optimierung der Switch-Port-Auslastung in KI-Fabrics bei.
Die Auswahl des optischen Moduls hängt von der Übertragungsdistanz, den Bandbreitenanforderungen, dem Stromverbrauch und der Einsatztopologie ab.
Die Verbindung zwischen Dornen und Blättern erfordert in der Regel Folgendes:
Höhere Bandbreite
Größere Reichweite
Singlemode-Faser für großflächige Installationen
In diesen Szenarien werden häufig 400G DR4-, FR4- und 800G-Optiken eingesetzt.
Die Verbindungen zwischen Leaf-Server und GPU-Server sind oft kürzer und können Folgendes nutzen:
DAC-Kabel für kurze Distanzen
AOCs für mittlere Reichweite
SR-Multimode-Optiken für flexible Rack-Layouts
Die richtige Wahl hängt von der Rackdichte und dem thermischen Design ab.
|
schaffen |
Vorteile |
Einschränkungen |
Typischer Anwendungsfall |
|---|---|---|---|
|
Glasfaseroptik |
Große Reichweite, hohe Bandbreite, Skalierbarkeit |
Höhere Kosten |
Wirbelsäulenblattgewebe |
|
DAC |
Geringe Kosten, geringer Stromverbrauch |
Sehr kurze Entfernung |
Verbindungen im selben Rack |
|
AOC |
Leicht, flexibel, größere Reichweite als DAC |
Höhere Kosten als DAC |
GPU-Verbindungen zwischen verschiedenen Racks |
In modernen KI-Clusternetzwerken werden bei den meisten großflächigen Implementierungen Glasfaser, DACs und AOCs kombiniert, um Kosten, Dichte, Energieeffizienz und Skalierbarkeit in Einklang zu bringen.
Die Bandbreitenplanung ist ein entscheidender Bestandteil des Netzwerkdesigns von KI-Clustern. Unzureichende Netzwerkbandbreite kann die GPU-Auslastung verringern, die Trainingszeit verlängern und zu Engpässen im gesamten Netzwerk führen. Die erforderliche Netzwerkkapazität hängt stark von der Art der Arbeitslast, der Clustergröße und den zukünftigen Skalierungsanforderungen ab.
Unterschiedliche KI-Workloads erzeugen sehr unterschiedliche Verkehrsmuster.
Das Training verteilter KI-Systeme erzeugt einen extrem hohen Ost-West-Datenverkehr, da GPUs während der Synchronisierungsvorgänge ständig Gradienten, Tensoren und Modellparameter austauschen.
Schulungsumgebungen erfordern typischerweise:
Extrem hoher Durchsatz
Geringe Latenz
RDMA-fähige Kommunikation
Niedrige Überbuchungsquoten
Große Cluster für das Training von Sprachmodellen (LLM) nutzen häufig 400G- oder 800G-Architekturen, um eine effiziente GPU-Synchronisierung zu gewährleisten.
Inferenzprozesse sind in der Regel weniger bandbreitenintensiv, da die Kommunikation zwischen den Knoten geringer ist.
Inferenznetzwerke priorisieren häufig:
Schnelle Antwortzeit
Skalierbarkeit der Anfragen
Kosteneffizienz
Flexible Bereitstellung
In vielen Inferenzumgebungen sind 100G- oder 400G-Ethernet-Netzwerke je nach Modellgröße und Datenverkehrsaufkommen ausreichend.
Der Bandbreitenbedarf steigt deutlich an, wenn KI-Workloads auf mehrere Server verteilt werden.
Einzelknoten-GPU-Server setzen hauptsächlich auf interne GPU-Verbindungen wie NVLink oder PCIe, wodurch die Abhängigkeit von externen Netzwerken reduziert wird.
Diese Umgebungen benötigen typischerweise weniger Bandbreite.
Bei Installationen mit mehreren Knoten entsteht ein deutlich höherer Netzwerkverkehr, da die GPUs die Daten kontinuierlich über die Server hinweg synchronisieren müssen.
Mit zunehmender Clustergröße:
Der Ost-West-Verkehr nimmt rapide zu.
Das Staurisiko steigt
Textilien mit geringer Latenz gewinnen an Bedeutung
Die Nachfrage nach optischen Verbindungen steigt
Große verteilte Trainingscluster benötigen oft nicht-blockierende 400G- oder 800G-Spine-Leaf-Architekturen.
Die Anforderungen an die KI-Infrastruktur entwickeln sich rasant. Viele Organisationen, die ursprünglich 100G-Netzwerke eingesetzt haben, rüsten jetzt auf 400G auf und bereiten sich auf die Skalierbarkeit auf 800G vor.
Bei der Planung von KI-Textilien ist Folgendes zu berücksichtigen:
Zukünftige GPU-Erweiterung
Zunehmende Modellgrößen
Höhere Rackdichte
Upgrade-Pfade für optische Module
Schaltleistung und Kühlleistung
Eine von vornherein auf zukünftige Skalierbarkeit ausgelegte Planung kann teure Netzwerk-Neugestaltungen später vermeiden.
Obwohl die Anforderungen je nach Arbeitslast variieren, werden in modernen KI-Netzwerken üblicherweise mehrere praktische Richtlinien angewendet.
Geeignet für:
Kleine GPU-Cluster
Inferenzumgebungen
Entwicklungs- und Testsysteme
Empfohlen für:
Mittelgroße bis große KI-Trainingscluster
Multi-Rack-GPU-Bereitstellungen
Hochleistungsfähige RoCEv2-Gewebe
Moderne Wirbelsäulen-Blatt-Architekturen
400G hat sich in vielen KI-Rechenzentren von Unternehmen zur Standardwahl entwickelt.
Am besten geeignet für:
Hyperscale KI-Infrastruktur
Ultragroßes verteiltes Training
Zukunftssichere GPU-Textilien
KI-Switch-Plattformen mit hoher Dichte
800G-Fabrics tragen zur Verbesserung der Skalierbarkeit, der Portdichte und der langfristigen Bandbreiteneffizienz bei, da KI-Workloads kontinuierlich zunehmen.
Selbst gut konzipierte KI-Cluster können Netzwerkprobleme aufweisen, die die GPU-Auslastung reduzieren und das verteilte Training verlangsamen. Da KI-Workloads sehr empfindlich auf Latenz und Netzwerküberlastung reagieren, können bereits kleine Netzwerkprobleme die Gesamtleistung des Clusters schnell beeinträchtigen.

Nachfolgend werden einige der häufigsten Probleme bei der Vernetzung von KI-Clustern und deren praktische Lösungen aufgeführt.
Unerwartete Latenzspitzen können die GPU-Synchronisierung unterbrechen und kollektive Kommunikationsvorgänge wie All-Reduce verlangsamen.
Häufige Ursachen sind:
Netzwerküberbelegung
Verstopfte Dorn-Blatt-Verbindungen
Unangemessene QoS-Richtlinien
Hohe CPU-Interruptlast
Ungleiche Verkehrsverteilung
Um Latenzspitzen zu reduzieren:
Verwenden Sie nicht blockierende oder wenig nachbestellte Stoffe.
Aktivieren Sie RDMA, wo möglich.
ECMP-Lastverteilung optimieren
Verbesserung der GPU- und NUMA-Affinitätsausrichtung
Auslastung des Überwachungsschalterpuffers
Eine konstant niedrige Latenz ist entscheidend für die Aufrechterhaltung eines effizienten verteilten KI-Trainings.
Paketverluste sind in KI-Trainingsumgebungen besonders schädlich, da erneute Übertragungen die Synchronisierung über Tausende von GPUs hinweg verzögern können.
Staus werden häufig verursacht durch:
Starker Ost-West-Verkehr
Unzureichende Uplink-Bandbreite
Mangelhaftes Warteschlangenmanagement
Verkehrsspitzen während des Kollektivbetriebs
Gängige Lösungen sind:
Einsatz verlustfreier Ethernet-Technologien
PFC und ECN korrekt konfigurieren
Erhöhung der Gewebebandbreite
Reduzierung der Überzeichnungsquoten
Nutzung intelligenter Staukontrollmechanismen
InfiniBand-Architekturen bieten typischerweise ein integriertes Stauungsmanagement, während RoCEv2-Umgebungen eine sorgfältigere Abstimmung erfordern.
Eine fehlerhafte RDMA-Konfiguration ist eine der häufigsten Ursachen für eine instabile Leistung von KI-Netzwerken.
Zu den typischen Problemen gehören:
Falsche MTU-Einstellungen
PFC-Fehlkonfiguration
Fehlerhafte DCB-Konfiguration
Ungleichgewicht in der RDMA-Warteschlange
Inkompatible Schaltereinstellungen
Symptome können sein:
GPU-Kommunikationsinstabilität
Niedrige NCCL-Leistung
Unerwartete Paketverluste
Hohe Latenz beim verteilten Training
Zur Verbesserung der RDMA-Stabilität:
Standardisierung der Netzwerkkonfiguration im gesamten Cluster
PFC- und ECN-Verhalten validieren
Verwenden Sie konsistente MTU-Einstellungen
Testen Sie die RDMA-Leistung regelmäßig.
Überwachung der NCCL-Kommunikationseffizienz
KI-Cluster sind stark von der Kompatibilität zwischen Netzwerkkarten, Switches, GPUs und Betriebssystemen abhängig. Firmware-Inkompatibilitäten können unvorhersehbare Leistungsprobleme oder RDMA-Fehler verursachen.
Häufige Problembereiche sind:
Inkonsistenzen in der NIC-Firmware
Software-Inkompatibilität des Schalters
GPU-Treiber-Inkompatibilitäten
Nicht unterstützte RDMA-Funktionsversionen
Zu den Best Practices gehören:
Standardisierung der Firmware-Versionen im gesamten Cluster
Kompatibilität vor Upgrades prüfen
Pflege dokumentierter Software-Baselines
Updates zunächst in Testumgebungen testen
Eine konsistente Firmware-Verwaltung ist für einen stabilen Betrieb von KI-Systemen im großen Maßstab unerlässlich.
Bei einigen KI-Clustern kommt es zu einer ungleichmäßigen Bandbreitennutzung, wobei bestimmte Verbindungen überlastet sind, während andere unterausgelastet bleiben.
Dies wird häufig verursacht durch:
Ineffizientes ECMP-Hashing
Schlechtes Topologie-Design
Verkehrsknotenpunkte
Unausgewogene GPU-Kommunikationspfade
Zur Verbesserung der Stoffausnutzung:
Optimierung des Spine-Leaf-Topologiedesigns
ECMP-Richtlinien anpassen
Ausgleich der Datenverkehrspfade über die Switches
Die Durchflussverteilung kontinuierlich überwachen
Nutzen Sie Telemetrie- und Textilanalysetools.
Eine effiziente Nutzung der Verbindungen trägt dazu bei, die verfügbare Bandbreite zu maximieren und die Skalierbarkeit des KI-Trainings insgesamt zu verbessern.

Das optimale Netzwerk für einen KI-Cluster hängt von der Arbeitslast, den Latenzanforderungen und dem Budget ab. Umfangreiche, verteilte KI-Trainingsumgebungen nutzen häufig InfiniBand aufgrund seiner extrem niedrigen Latenz und der hohen RDMA-Leistung. KI-Implementierungen in Unternehmen entscheiden sich üblicherweise für RoCEv2 über Ethernet, um ein ausgewogenes Verhältnis zwischen Skalierbarkeit, Kosten und operativer Flexibilität zu erzielen.
InfiniBand bietet im Allgemeinen geringere Latenz und ein ausgereifteres Stau-Management für hyperskalierbare KI-Trainingscluster. RoCEv2 hat sich jedoch als beliebte Alternative etabliert, da es die Leistungsfähigkeit von RDMA mit der Standard-Ethernet-Infrastruktur kombiniert, wodurch die Bereitstellungskosten gesenkt und die Kompatibilität mit Unternehmensnetzwerken verbessert werden.
Für viele Organisationen bietet RoCEv2 das beste Gleichgewicht zwischen Leistung und Skalierbarkeit.
Moderne KI-Trainingscluster setzen zunehmend auf optische 400G- und 800G-Module, um eine GPU-Kommunikation mit hoher Bandbreite zu ermöglichen.
400G-Optiken sind mittlerweile Standard bei mittelgroßen bis großen KI-Implementierungen.
800G-Optiken werden hauptsächlich in Hyperscale- und KI-Gebäuden der nächsten Generation eingesetzt.
Kleinere Inferenzcluster und Entwicklungsumgebungen können auch mit 100G-Netzwerken effizient arbeiten.
Ja. Moderne Ethernet-Netzwerke in Kombination mit RoCEv2- und RDMA-Technologien ermöglichen ein effektives Training von KI-Systemen im großen Maßstab. Viele KI-Rechenzentren in Unternehmen nutzen mittlerweile Hochgeschwindigkeits-Ethernet mit verlustfreien Netzwerkkonfigurationen für verteilte GPU-Workloads.
Allerdings erfordern Ethernet-basierte KI-Architekturen eine sorgfältige Abstimmung von Technologien wie:
PFC (Prioritätsflusskontrolle)
ECN (Explizite Überlastungsbenachrichtigung)
DCB (Data Center Bridging)
Ohne die richtige Konfiguration können Überlastung und Paketverlust die Trainingseffizienz beeinträchtigen.
Optische Module haben einen direkten Einfluss auf Bandbreite, Latenz, Skalierbarkeit und Signalzuverlässigkeit in KI-Clusternetzwerken.
Hochgeschwindigkeits-Transceiver wie QSFP-DD- und OSFP-Module ermöglichen:
400G- und 800G-Konnektivität
Fernkommunikation zwischen Dornen und Blättern
GPU-Gewebe mit hoher Dichte
Geringere Signalbeeinträchtigung
Bessere Skalierbarkeit für verteilte KI-Workloads
Die Wahl der richtigen Optik für Switch-zu-Switch- und Switch-zu-Server-Verbindungen trägt zur Verbesserung der Gesamtleistung des KI-Clusters und der zukünftigen Skalierbarkeit bei.
Da die KI-Infrastruktur zunehmend auf größere GPU-Cluster und 400G/800G-Netzwerke setzt, wirken sich die heutigen Netzwerkdesignentscheidungen direkt auf die langfristige Skalierbarkeit, die Betriebsstabilität und die Bereitstellungskosten aus. Erfolgreiche KI-Cluster-Netzwerkprojekte konzentrieren sich nicht mehr nur auf die reine Bandbreite, sondern priorisieren auch Beobachtbarkeit, Interoperabilität und zukünftige optische Skalierbarkeit.

KI-Cluster erzeugen enorme Mengen an Ost-West-Datenverkehr, weshalb Transparenz und Überwachung unerlässlich sind. Moderne KI-Infrastrukturen sollten Folgendes umfassen:
Echtzeit-Telemetrie
Stauüberwachung
RDMA-Leistungsanalyse
GPU-Kommunikationssichtbarkeit
Schalter- und optische Diagnostik
Die frühzeitige Beobachtbarkeit hilft dabei, Engpässe zu erkennen, bevor sie die GPU-Auslastung und die Trainingseffizienz beeinträchtigen.
Die Abhängigkeit von einem einzelnen Anbieter kann die zukünftige Skalierbarkeit einschränken und die Infrastrukturkosten erhöhen. Organisationen sollten KI-Infrastrukturen daher nach Möglichkeit auf Basis offener Ethernet-Standards, interoperabler Optiken und flexibler Spine-Leaf-Architekturen entwickeln.
Eine herstellerneutrale Strategie verbessert Folgendes:
Hardware-Flexibilität
Upgrade-Optionen
Langfristige Kostenkontrolle
Herstellerübergreifende Kompatibilität
Firmware-Inkonsistenzen zählen zu den häufigsten Ursachen für Instabilität in KI-Netzwerken. Die Standardisierung von Netzwerkkarten-Firmware, Switch-Software, optischen Modulen und Kabeltypen trägt dazu bei, unerwartete Interoperabilitätsprobleme zu reduzieren.
Zu den Best Practices gehören:
Aufrechterhaltung konsistenter Firmware-Versionen
Verwendung validierter optischer Kompatibilitätslisten
Standardisierung von DAC, AOC und Glasfaserausbau
Upgrades vor der Produktionsfreigabe testen
Große KI-Systeme können extrem komplex werden. Eine ordnungsgemäße Dokumentation vereinfacht die Fehlersuche und zukünftige Erweiterungen.
Wichtige zu dokumentierende Punkte sind:
Spine-Leaf-Topologie-Design
RDMA- und RoCE-Einstellungen
ECMP-Richtlinien
Überzeichnungsquoten
Pläne für den Einsatz optischer Module
NCCL-Tuningparameter
Gut dokumentierte Umgebungen lassen sich im Laufe der Zeit leichter skalieren und warten.
Das zukünftige Wachstum der KI erfordert weit mehr als zusätzliche Switch-Ports. Optische Bandbreitendichte, Energieeffizienz und Kabelmanagement werden zu ebenso wichtigen Designfaktoren.
Organisationen, die neue KI-Infrastrukturen einführen, sollten sich bereits jetzt auf Folgendes vorbereiten:
400G-zu-800G-Migrationspfade
Höhere Rackdichte
OSFP- und QSFP-DD800-Einführung
Skalierbare Glasfaserinfrastruktur
Zukünftige Ultra-Cluster-Architekturen
Die frühzeitige Wahl des richtigen optischen Ökosystems kann die Komplexität zukünftiger Upgrades erheblich reduzieren.
Da sich die Vernetzung von KI-Clustern stetig weiterentwickelt, bleiben hochwertige optische Verbindungen und zuverlässige Ethernet-Komponenten die Grundlage für eine skalierbare GPU-Infrastruktur. Für Unternehmen, die moderne KI-Netzwerke planen, LINK-PP Offizieller Shop bietet eine breite Palette an optischen Hochgeschwindigkeitsmodulen, DAC/AOC-Lösungen und Netzwerkverbindungsprodukten, die für den Einsatz in KI-, HPC- und Rechenzentrumsumgebungen von Unternehmen entwickelt wurden.

Melden Sie sich an oder erstellen Sie ein Konto, um Ihre Anfrage online zu verfolgen.