

























Ζωντανή Συζήτηση
Είμαστε εδώ για να βοηθήσουμε 24/7.
Στείλτε μας μήνυμα τώρα για μια γρήγορη απάντηση.
Όλες οι κατηγορίες
Ενότητες SFP
Υπηρεσίες
Υποστήριξη
Σχετικά με εμάς
Υποστηρικτικό υλικό


Προσέξτε την επιχείρησή σας με μια ποικιλία από αξιόπιστες επιλογές πληρωμής.
Χρησιμοποιήστε τον αριθμό παραγγελίας ή τον αριθμό παρακολούθησης για να ελέγξετε την κατάσταση αποστολής.
Λάβετε γρήγορα την προσφορά σας και προσφέρετε πιο επαγγελματική εξυπηρέτηση.
Βοηθήστε να διαχειριστείτε καλύτερα τον προϋπολογισμό και τις δαπάνες σας.
Δωρεάν υποστήριξη δειγμάτων, επιτύχετε τα αποτελέσματα των δοκιμών σας αποτελεσματικά.
Επαγγελματική υποστήριξη και εξυπηρέτηση ομάδας, για την έγκαιρη επίλυση των προβλημάτων σας.
Ρωτήστε μας για οτιδήποτε σας απασχολεί, θα σας βοηθήσουμε 24/7.
Λάβετε την προσφορά σας γρήγορα και σας προσφέρουμε πιο επαγγελματική εξυπηρέτηση.
Γνωρίστε μας και γνωρίστε την αποστολή, τις πεποιθήσεις μας, την υπηρεσία και πολλά άλλα.
Βρείτε τις τοποθεσίες μας και συνδεθείτε στενά μαζί μας.
Εξερευνήστε πώς νοιαζόμαστε για την ποιότητα.
Μάθετε τα πιο πρόσφατα νέα και τα γεγονότα γύρω l-p.com
Εμβάθυνση σε τεχνικούς οδηγούς, πρότυπα του κλάδου και πληροφορίες για τη συμβατότητα με SFP.
Λεπτομερή benchmarks προϊόντων και συγκρίσεις μεταξύ τους που θα σας βοηθήσουν να επιλέξετε τη σωστή ενότητα.
Εξερευνήστε λύσεις συνδεσιμότητας σε πραγματικό κόσμο για κέντρα δεδομένων, επιχειρήσεις και τηλεπικοινωνιακά δίκτυα.
Βασικές συμβουλές για την επιλογή ρυθμών δεδομένων, αποστάσεων μετάδοσης και τύπων συνδέσμων.





Καθώς τα μοντέλα Τεχνητής Νοημοσύνης (AI) συνεχίζουν να κλιμακώνονται, η δικτύωση έχει γίνει εξίσου σημαντική με την απόδοση της GPU. Τα σύγχρονα φόρτα εργασίας Τεχνητής Νοημοσύνης (AI) βασίζονται σε κατανεμημένα συμπλέγματα GPU που δημιουργούν τεράστια κίνηση ανατολικά-δυτικά κατά την εκπαίδευση και την εξαγωγή συμπερασμάτων, καθιστώντας τη δικτύωση χαμηλής καθυστέρησης και υψηλού εύρους ζώνης απαραίτητη για τη συνολική απόδοση του συστήματος.
Εδώ είναι που Δικτύωση συμπλεγμάτων τεχνητής νοημοσύνης παίζει κρίσιμο ρόλο.
Η δικτύωση συμπλεγμάτων τεχνητής νοημοσύνης αναφέρεται στην υποδομή δικτύου υψηλής απόδοσης που συνδέει διακομιστές GPU, συστήματα αποθήκευσης και επιταχυντές τεχνητής νοημοσύνης εντός κέντρων δεδομένων τεχνητής νοημοσύνης και περιβαλλόντων HPC. Σε αντίθεση με τα παραδοσιακά εταιρικά δίκτυα, τα συμπλέγματα τεχνητής νοημοσύνης απαιτούν εξαιρετικά γρήγορη επικοινωνία μεταξύ κόμβων για την υποστήριξη κατανεμημένων υπολογιστικών πλαισίων, όπως η επικοινωνία GPU που βασίζεται σε NCCL και RDMA.
Για τη μείωση των σημείων συμφόρησης και τη μεγιστοποίηση της αξιοποίησης της GPU, τα σύγχρονα δίκτυα τεχνητής νοημοσύνης χρησιμοποιούν συνήθως τεχνολογίες όπως:
InfiniBand
RoCEv2 και RDMA
Απρόσκοπτη υφή Ethernet
Αρχιτεκτονικές δικτύου spine-leaf
Οπτικές διασυνδέσεις 400G και 800G
Στο φυσικό επίπεδο, οι οπτικές μονάδες έχουν γίνει βασικό μέρος του σχεδιασμού υποδομών τεχνητής νοημοσύνης. Οι πομποδέκτες υψηλής ταχύτητας, όπως οι μονάδες QSFP-DD και OSFP, επιτρέπουν την κλιμακούμενη συνδεσιμότητα 400G και 800G μεταξύ διακοπτών και διακομιστών GPU, διατηρώντας παράλληλα χαμηλή καθυστέρηση και υψηλή πυκνότητα θυρών.
Σε αυτόν τον οδηγό, θα εξηγήσουμε πώς λειτουργεί η δικτύωση συμπλεγμάτων τεχνητής νοημοσύνης, θα συγκρίνουμε τις αρχιτεκτονικές InfiniBand και RoCEv2, θα εξετάσουμε τις τεχνολογίες RDMA και ελέγχου συμφόρησης και θα διερευνήσουμε πώς οι οπτικές μονάδες υποστηρίζουν τη σύγχρονη επεκτασιμότητα συμπλεγμάτων τεχνητής νοημοσύνης το 2025 και μετά.
Η δικτύωση συμπλεγμάτων τεχνητής νοημοσύνης αναφέρεται στο υψηλής απόδοσης δίκτυο που χρησιμοποιείται για τη σύνδεση διακομιστών GPU, επιταχυντών τεχνητής νοημοσύνης, συστημάτων αποθήκευσης και διακοπτών εντός κέντρων δεδομένων τεχνητής νοημοσύνης και περιβαλλόντων υπολογιστικής υψηλής απόδοσης (HPC). Ο κύριος σκοπός του είναι να επιτρέπει την εξαιρετικά γρήγορη ανταλλαγή δεδομένων μεταξύ υπολογιστικών κόμβων κατά τη διάρκεια κατανεμημένων φόρτων εργασίας τεχνητής νοημοσύνης.
Από πρακτικής άποψης, η δικτύωση συμπλεγμάτων τεχνητής νοημοσύνης έχει σχεδιαστεί για να λύσει ένα κρίσιμο πρόβλημα: τη διατήρηση της πλήρους αξιοποίησης των GPU κατά τη διάρκεια εργασιών εκπαίδευσης και συμπερασμάτων μεγάλης κλίμακας. Δεδομένου ότι τα σύγχρονα μοντέλα τεχνητής νοημοσύνης είναι πολύ μεγάλα για να εκτελούνται αποτελεσματικά σε μία μόνο GPU ή ακόμα και σε έναν μόνο διακομιστή, τα φόρτα εργασίας κατανέμονται σε πολλαπλούς κόμβους που πρέπει να συγχρονίζουν συνεχώς τα δεδομένα μεταξύ τους. Επομένως, το δίκτυο γίνεται μέρος του ίδιου του υπολογιστικού συστήματος και όχι απλώς ένα επίπεδο μεταφοράς.
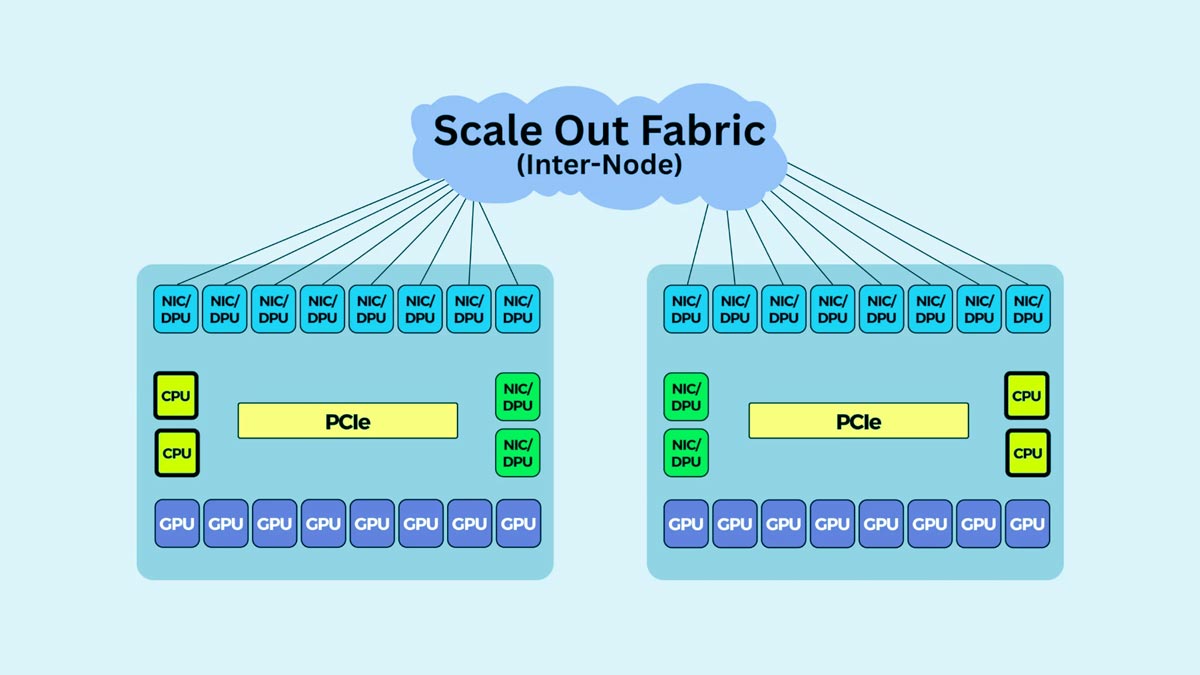
Σε αντίθεση με τα συμβατικά εταιρικά δίκτυα που χειρίζονται κυρίως την επικοινωνία μεταξύ χρήστη και διακομιστή, τα clusters τεχνητής νοημοσύνης παράγουν τεράστιες ποσότητες... κυκλοφορία ανατολής-δύσης — δεδομένα που μετακινούνται πλευρικά μεταξύ GPU, διακομιστών και συστημάτων αποθήκευσης εντός του κέντρου δεδομένων.
Η κατανεμημένη εκπαίδευση τεχνητής νοημοσύνης απαιτεί από τις GPU να ανταλλάσσουν συνεχώς κλίσεις, τανυστές, παραμέτρους μοντέλου και δεδομένα συγχρονισμού. Κατά τη διάρκεια λειτουργιών όπως ο παραλληλισμός δεδομένων, ο παραλληλισμός τανυστών και ο παραλληλισμός αγωγών, κάθε GPU μπορεί να επικοινωνεί με πολλές άλλες GPU ταυτόχρονα.
Αυτό δημιουργεί μοτίβα κυκλοφορίας από ανατολή προς δύση με εξαιρετικά μεγάλο εύρος ζώνης.
Για παράδειγμα, κατά τη διάρκεια της εκπαίδευσης σε μεγάλο γλωσσικό μοντέλο (LLM), οι GPU εκτελούν συχνά συλλογικές λειτουργίες επικοινωνίας, όπως:
Μείωση όλων
Όλος-Συγκεντρωθείτε
Αναμετάδοση
Μείωση-Διασπορά
Αυτές οι λειτουργίες δημιουργούν μεγάλη διακόμβικη κίνηση που είναι ιδιαίτερα ευαίσθητη σε:
Αφάνεια
Απώλεια πακέτων
Συμφόρηση
jitter
Υπερσυνδρομή δικτύου
Ακόμα και μικρές καθυστερήσεις στον συγχρονισμό μπορούν να αφήσουν τις ακριβές GPU σε αδράνεια, μειώνοντας σημαντικά την απόδοση του cluster και αυξάνοντας τον χρόνο εκπαίδευσης.
Εξαιτίας αυτού, τα περιβάλλοντα δικτύωσης Τεχνητής Νοημοσύνης αναπτύσσουν συνήθως:
Τοπολογίες μη μπλοκαρίσματος spine-leaf
Υφάσματα με δυνατότητα RDMA
Ethernet χωρίς απώλειες ή InfiniBand
Οπτικές διασυνδέσεις 400G και 800G
Ευφυείς μηχανισμοί ελέγχου συμφόρησης
Ο στόχος είναι η ελαχιστοποίηση του φόρτου επικοινωνίας και η διατήρηση προβλέψιμης απόδοσης χαμηλής καθυστέρησης σε όλο το σύμπλεγμα.
Παρόλο που τόσο η εκπαίδευση στην Τεχνητή Νοημοσύνη όσο και η συμπερασματική ανάλυση βασίζονται σε δικτύωση υψηλής ταχύτητας, τα πρότυπα κυκλοφορίας και οι απαιτήσεις υποδομής τους είναι πολύ διαφορετικά.
Τα περιβάλλοντα εκπαίδευσης τεχνητής νοημοσύνης δίνουν προτεραιότητα σε:
Εξαιρετικά χαμηλή καθυστέρηση
υψηλής απόδοσης
Αποδοτικότητα συγχρονισμού GPU
Μεγάλη χωρητικότητα εύρους ζώνης ανατολής-δύσης
RDMA και συλλογική βελτιστοποίηση επικοινωνίας
Τα εκπαιδευτικά clusters χρησιμοποιούν συχνά υφάσματα InfiniBand ή RoCEv2 με οπτικές μονάδες 400G/800G για την υποστήριξη συνεχούς επικοινωνίας GPU-προς-GPU σε μεγάλη κλίμακα.
Τα φόρτα εργασίας συμπερασμάτων συνήθως επικεντρώνονται περισσότερο σε:
Γρήγορος χρόνος απόκρισης
Επεκτασιμότητα για αιτήματα χρηστών
Διαχείριση κυκλοφορίας Βορρά-Νότου
Αποδοτικότητα κόστους
Εξισορρόπηση φορτίου
Τα συμπλέγματα συμπερασμάτων ενδέχεται να μην απαιτούν το ίδιο επίπεδο συγχρονισμού εξαιρετικά χαμηλής καθυστέρησης όπως τα περιβάλλοντα εκπαίδευσης, ειδικά για φόρτους εργασίας συμπερασμάτων ενός κόμβου ή ελαφρώς κατανεμημένους. Σε πολλές περιπτώσεις, τα υψηλής ταχύτητας δίκτυα Ethernet είναι επαρκή.
Ωστόσο, καθώς οι εφαρμογές κατανεμημένης συμπερασματολογίας μεγάλης κλίμακας και οι εφαρμογές γενετικής τεχνητής νοημοσύνης σε πραγματικό χρόνο συνεχίζουν να αναπτύσσονται, οι απαιτήσεις δικτύωσης συμπερασματολογίας γίνονται επίσης πιο απαιτητικές, ειδικά για αρχιτεκτονικές εξυπηρέτησης τεχνητής νοημοσύνης πολλαπλών κόμβων.
Η επιλογή της σωστής αρχιτεκτονικής δικτύωσης συμπλεγμάτων τεχνητής νοημοσύνης επηρεάζει άμεσα την αξιοποίηση της GPU, την καθυστέρηση, την επεκτασιμότητα και το κόστος ανάπτυξης. Σήμερα, οι περισσότερες υποδομές τεχνητής νοημοσύνης βασίζονται σε τρεις κύριες προσεγγίσεις: InfiniBand, RoCEv2 και τυπικό Ethernet.
Το InfiniBand χρησιμοποιείται ευρέως σε περιβάλλοντα εκπαίδευσης υπερκλίμακας τεχνητής νοημοσύνης και HPC, επειδή προσφέρει εξαιρετικά χαμηλή καθυστέρηση, υψηλή απόδοση και προηγμένο έλεγχο συμφόρησης. Είναι βελτιστοποιημένο για επικοινωνία RDMA και GPU μεγάλης κλίμακας, καθιστώντας το ιδανικό για κατανεμημένα φόρτα εργασίας εκπαίδευσης τεχνητής νοημοσύνης.
Τα βασικά πλεονεκτήματα περιλαμβάνουν:
Εξαιρετικά χαμηλή καθυστέρηση
Υψηλή απόδοση επικοινωνίας GPU
Ισχυρή απόδοση RDMA
Εξαιρετική επεκτασιμότητα για μεγάλα clusters
Ωστόσο, το InfiniBand έχει επίσης υψηλότερο κόστος και μεγαλύτερη πολυπλοκότητα ανάπτυξης, καθιστώντας το καταλληλότερο για:
Μεγάλα clusters εκπαίδευσης Τεχνητής Νοημοσύνης
Περιβάλλοντα HPC
Αναπτύξεις GPU πολλαπλών ραφιών
Το RoCEv2 (RDMA μέσω Converged Ethernet) φέρνει δυνατότητες RDMA σε δίκτυα Ethernet. Προσφέρει μια ισχυρή ισορροπία μεταξύ απόδοσης, επεκτασιμότητας και κόστους, ενώ παράλληλα ενσωματώνεται πιο εύκολα με την εταιρική υποδομή.
Τα οφέλη του RoCEv2 περιλαμβάνουν:
Χαμηλότερο κόστος από το InfiniBand
Συμβατότητα Ethernet υψηλής ταχύτητας
Καλή επεκτασιμότητα για φόρτους εργασίας τεχνητής νοημοσύνης
Ευκολότερη ενσωμάτωση σε επιχειρήσεις
Για την επίτευξη σταθερής απόδοσης, το RoCEv2 απαιτεί σωστή διαμόρφωση τεχνολογιών Ethernet χωρίς απώλειες, όπως PFC και ECN.
Το RoCEv2 χρησιμοποιείται συνήθως σε:
Συστάδες Τεχνητής Νοημοσύνης για επιχειρήσεις
Υποδομή τεχνητής νοημοσύνης στο cloud
Μεσαία έως μεγάλα περιβάλλοντα GPU
Το τυπικό Ethernet παραμένει μια πρακτική επιλογή για μικρότερες αναπτύξεις τεχνητής νοημοσύνης και συμπλέγματα συμπερασμάτων όπου ο συγχρονισμός GPU με εξαιρετικά χαμηλή καθυστέρηση είναι λιγότερο κρίσιμος.
Τα πλεονεκτήματα περιλαμβάνουν:
Χαμηλότερο κόστος ανάπτυξης
Απλοποιημένη διαχείριση
Ευρεία συμβατότητα
Ευέλικτη κλιμάκωση
Τα σύγχρονα δίκτυα Ethernet 100G και 400G μπορούν να υποστηρίξουν αποτελεσματικά πολλά φόρτα εργασίας συμπερασμού τεχνητής νοημοσύνης, αν και ενδέχεται να μην ταιριάζουν με τα δίκτυα που βασίζονται σε RDMA για κατανεμημένη εκπαίδευση μεγάλης κλίμακας.
|
Χαρακτηριστικό |
InfiniBand |
RoCEv2 |
Ethernet |
|---|---|---|---|
|
Αφάνεια |
Χαμηλότερη |
Πολύ χαμηλά |
Μέτρια |
|
Υποστήριξη RDMA |
Native |
υποστηριζόνται! |
Περιωρισμένος |
|
Κόστος |
Υψιστος |
Μέτριας Δυσκολίας |
Χαμηλότερη |
|
Περίπλοκο |
Ψηλά |
Μέτριας Δυσκολίας |
Χαμηλός |
|
Καλύτερη περίπτωση χρήσης |
Εκπαίδευση σε μεγάλες ομάδες Τεχνητής Νοημοσύνης |
Συστάδες Τεχνητής Νοημοσύνης για επιχειρήσεις |
Συμπερασματολογία και μικρότερες αναπτύξεις |
Γενικά, το InfiniBand παραμένει η κορυφαία επιλογή για μέγιστη απόδοση εκπαίδευσης στην Τεχνητή Νοημοσύνη, το RoCEv2 παρέχει την καλύτερη ισορροπία κόστους και επεκτασιμότητας και το τυπικό Ethernet είναι συχνά επαρκές για περιβάλλοντα Τεχνητής Νοημοσύνης που επικεντρώνονται στην εξαγωγή συμπερασμάτων.
Ο σχεδιασμός ενός δικτύου τεχνητής νοημοσύνης με χαμηλή καθυστέρηση είναι κρίσιμος για τη διατήρηση υψηλής αξιοποίησης της GPU και την αποτελεσματική κατανεμημένη εκπαίδευση. Στα σύγχρονα clusters τεχνητής νοημοσύνης, το δίκτυο πρέπει να υποστηρίζει μαζική κίνηση ανατολικά-δυτικά με ελάχιστη συμφόρηση, απώλεια πακέτων και καθυστέρηση συγχρονισμού.
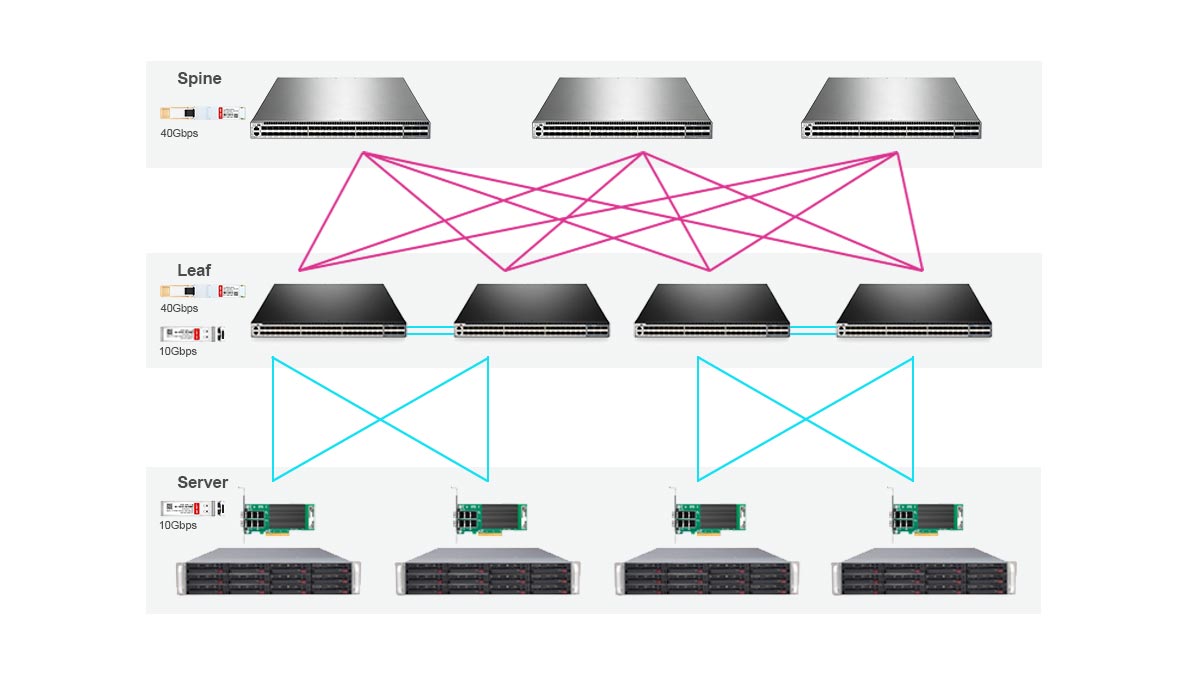
Τα περισσότερα clusters τεχνητής νοημοσύνης χρησιμοποιούν ένα τοπολογία φύλλου ράχης επειδή παρέχει προβλέψιμη επικοινωνία χαμηλής καθυστέρησης και κλιμακωτό εύρος ζώνης σε όλους τους κόμβους της GPU.
Σε αυτήν την αρχιτεκτονική:
Οι διακόπτες Leaf συνδέονται απευθείας με διακομιστές GPU.
Οι διακόπτες σπονδυλικής στήλης διασυνδέουν όλους τους διακόπτες φύλλων
Κάθε αλλαγή φύλλων έχει διαδρομές ίσου κόστους προς άλλα φύλλα
Αυτός ο σχεδιασμός ελαχιστοποιεί τα σημεία συμφόρησης και υποστηρίζει μοτίβα κυκλοφορίας υψηλού εύρους ζώνης από ανατολή προς δύση, τα οποία είναι συνηθισμένα στην εκπαίδευση στην τεχνητή νοημοσύνη.
Οι μεγάλες αναπτύξεις Τεχνητής Νοημοσύνης συχνά στοχεύουν σε ένα ύφασμα που δεν μπλοκάρει, όπου το δίκτυο παρέχει αρκετό εύρος ζώνης για να αποφύγει τη διαμάχη μεταξύ των κόμβων κατά τη διάρκεια λειτουργιών επικοινωνίας GPU, όπως το All-Reduce και το All-Gather.
Η υπερεγγραφή συμβαίνει όταν το διαθέσιμο εύρος ζώνης ανερχόμενης ζεύξης είναι χαμηλότερο από το συνολικό εύρος ζώνης που βρίσκεται απέναντι από τον διακομιστή.
Για τα clusters εκπαίδευσης τεχνητής νοημοσύνης, η χαμηλή υπερσυνδρομή είναι σημαντική, επειδή τα κατανεμημένα φόρτα εργασίας GPU δημιουργούν συνεχή διακόμβικη κίνηση. Η υψηλή υπερσυνδρομή μπορεί να αυξήσει την καθυστέρηση και να μειώσει την αποτελεσματικότητα της εκπαίδευσης.
Οι συνήθεις προσεγγίσεις περιλαμβάνουν:
Σχεδιασμοί χωρίς αποκλεισμούς 1:1 για μεγάλα clusters εκπαίδευσης τεχνητής νοημοσύνης
Χαμηλοί λόγοι υπερεγγραφής για μεσαίες αναπτύξεις GPU
Υψηλότερη υπερεγγραφή για περιβάλλοντα που εστιάζουν στην εξαγωγή συμπερασμάτων
Η ιδανική αναλογία εξαρτάται από τον τύπο φόρτου εργασίας, τον αριθμό των GPU και τους περιορισμούς του προϋπολογισμού.
Τα φόρτα εργασίας τεχνητής νοημοσύνης είναι ιδιαίτερα ευαίσθητα στην απώλεια πακέτων και τη συμφόρηση. Ακόμη και μικρές διακοπές δικτύου μπορούν να επιβραδύνουν την κατανεμημένη εκπαίδευση και να αφήσουν τις GPU σε αδράνεια.
Για τη βελτίωση της σταθερότητας, τα υφάσματα τεχνητής νοημοσύνης χρησιμοποιούν συνήθως:
Μεταφορά με δυνατότητα RDMA
Έλεγχος ροής προτεραιότητας (PFC)
Ρητή Ειδοποίηση Συμφόρησης (ECN)
Γεφύρωση Κέντρων Δεδομένων (DCB)
Αυτές οι τεχνολογίες συμβάλλουν στη δημιουργία ενός πιο προβλέψιμου περιβάλλοντος με χαμηλή καθυστέρηση για την επικοινωνία της GPU.
Το InfiniBand παρέχει ενσωματωμένη διαχείριση συμφόρησης, ενώ οι αναπτύξεις RoCEv2 που βασίζονται σε Ethernet απαιτούν προσεκτική ρύθμιση για να διατηρηθεί η συμπεριφορά χωρίς απώλειες.
Η βελτιστοποίηση σε επίπεδο εφαρμογής είναι επίσης απαραίτητη για την απόδοση των δικτύων τεχνητής νοημοσύνης.
Το NVIDIA NCCL (NVIDIA Collective Communications Library) χρησιμοποιείται ευρέως για επικοινωνία πολλαπλών GPU και εξαρτάται σε μεγάλο βαθμό από την αποτελεσματική μεταφορά δικτύου. Η σωστή διαμόρφωση RDMA βοηθά στη μείωση του φόρτου της CPU και στη βελτίωση της αποτελεσματικότητας της μεταφοράς δεδομένων από GPU σε GPU.
Οι συνήθεις τομείς βελτιστοποίησης περιλαμβάνουν:
Ρύθμιση τοπολογίας NCCL
Ρύθμιση ουράς RDMA
Συγγένεια GPU και ευθυγράμμιση NUMA
Βελτιστοποίηση MTU
Εξισορρόπηση διαδρομής κυκλοφορίας
Μαζί, αυτές οι βελτιστοποιήσεις σε επίπεδο δικτύου και εφαρμογής βοηθούν στη μείωση του φόρτου επικοινωνίας και στη βελτίωση της κλιμάκωσης της κατανεμημένης εκπαίδευσης της Τεχνητής Νοημοσύνης.
Οι οπτικές μονάδες αποτελούν βασικό στοιχείο της σύγχρονης δικτύωσης συμπλεγμάτων τεχνητής νοημοσύνης. Καθώς τα συμπλέγματα GPU κλιμακώνονται από εκατοντάδες σε χιλιάδες επιταχυντές, το δίκτυο πρέπει να παρέχει εξαιρετικά υψηλό εύρος ζώνης, χαμηλή καθυστέρηση και αξιόπιστη ακεραιότητα σήματος σε διακομιστές και διακόπτες. Αυτό έχει καταστήσει τις οπτικές διασυνδέσεις υψηλής ταχύτητας απαραίτητες στα κέντρα δεδομένων τεχνητής νοημοσύνης.
Η κατανεμημένη εκπαίδευση τεχνητής νοημοσύνης δημιουργεί τεράστια κίνηση από ανατολή προς δύση μεταξύ των κόμβων της GPU. Η καλωδίωση χαλκού από μόνη της δεν μπορεί να υποστηρίξει αποτελεσματικά συνδεσιμότητα μεγάλων αποστάσεων, υψηλής πυκνότητας 400G και 800G μέσα σε μεγάλα clusters τεχνητής νοημοσύνης.
Οι οπτικές μονάδες βοηθούν στην επίλυση αρκετών κρίσιμων προκλήσεων:
Επικοινωνία GPU υψηλού εύρους ζώνης
Μετάδοση δεδομένων με χαμηλή καθυστέρηση
Κλιμακούμενη επέκταση υφάσματος με ράχη
Μειωμένη υποβάθμιση σήματος σε απόσταση
Βελτιωμένη διαχείριση καλωδίων σε πυκνά rack
Καθώς οι συστάδες τεχνητής νοημοσύνης συνεχίζουν να αναπτύσσονται, η οπτική δικτύωση καθίσταται ολοένα και πιο σημαντική για τη διατήρηση σταθερής απόδοσης και υψηλής αξιοποίησης της GPU.
Οι σύγχρονες υποδομές τεχνητής νοημοσύνης μεταβαίνουν ραγδαία από δίκτυα 100G σε δίκτυα 400G και 800G.
Οι πομποδέκτες 100G εξακολουθούν να είναι συνηθισμένοι σε μικρότερα clusters GPU, δίκτυα αποθήκευσης και παλαιότερα περιβάλλοντα τεχνητής νοημοσύνης.
Τυπικές περιπτώσεις χρήσης περιλαμβάνουν:
Μικρά clusters εκπαίδευσης Τεχνητής Νοημοσύνης
Δίκτυα συμπερασμάτων
Διασυνδέσεις αποθήκευσης
Αναπτύξεις Edge AI
Το 400G έχει γίνει η κύρια επιλογή για πολλές εταιρικές και υπερκλιμακωτές αναπτύξεις τεχνητής νοημοσύνης, επειδή παρέχει σημαντικά υψηλότερο εύρος ζώνης για κατανεμημένη επικοινωνία GPU.
Οι συνήθεις οπτικές μονάδες 400G περιλαμβάνουν:
QSFP-DD SR8
QSFP-DD DR4
QSFP-DD FR4
Αυτές οι ενότητες χρησιμοποιούνται ευρέως για συνδεσιμότητα από σπονδυλική στήλη σε φύλλο και από φύλλο σε διακομιστή σε σύγχρονα υφάσματα τεχνητής νοημοσύνης.
Η δικτύωση 800G αναδύεται σε clusters τεχνητής νοημοσύνης επόμενης γενιάς που έχουν σχεδιαστεί για εκπαίδευση εξαιρετικά μεγάλων μοντέλων και αναπτύξεις GPU υψηλής πυκνότητας.
Οι πομποδέκτες 800G OSFP και QSFP-DD800 βοηθούν στην αύξηση:
διακίνηση δικτύου
Πυκνότητα λιμένα
Επεκτασιμότητα υφάσματος
Ικανότητα προετοιμασίας για το μέλλον
Δύο βασικοί παράγοντες μορφής κυριαρχούν στα δίκτυα τεχνητής νοημοσύνης σήμερα:
Οι μονάδες QSFP-DD υιοθετούνται ευρέως επειδή προσφέρουν υψηλή πυκνότητα θυρών και ισχυρή συμβατότητα με τα υπάρχοντα οικοσυστήματα Ethernet.
Χρησιμοποιούνται συνήθως για:
100G
200G
400G
Ανάπτυξη 800G
Οι μονάδες OSFP έχουν σχεδιαστεί για υψηλότερη ισχύ και θερμική απόδοση, καθιστώντας τες ολοένα και πιο δημοφιλείς σε υφάσματα τεχνητής νοημοσύνης 800G.
Το OSFP προτιμάται συχνά σε:
Υπερκλιμακωτές συστάδες τεχνητής νοημοσύνης
Περιβάλλοντα δικτύωσης GPU υψηλής ισχύος
Πλατφόρμες διακόπτη εξαιρετικά υψηλής πυκνότητας
Η συνδεσιμότητα Breakout επιτρέπει σε μία θύρα υψηλής ταχύτητας να χωριστεί σε πολλαπλές συνδέσεις χαμηλότερης ταχύτητας, όπως:
400G έως 4×100G
800G έως 2×400G
800G έως 8×100G
Τα σχέδια διακλάδωσης βελτιώνουν την ευελιξία και βοηθούν στη βελτιστοποίηση της αξιοποίησης των θυρών διακόπτη σε υφάσματα τεχνητής νοημοσύνης.
Η επιλογή της οπτικής μονάδας εξαρτάται από την απόσταση σύνδεσης, τις απαιτήσεις εύρους ζώνης, την κατανάλωση ενέργειας και την τοπολογία ανάπτυξης.
Οι συνδέσεις ράχης-φύλλου συνήθως απαιτούν:
Υψηλότερο εύρος ζώνης
Μεγαλύτερη εμβέλεια
Μονότροπη οπτική ίνα για εφαρμογές μεγάλης κλίμακας
Τα οπτικά συστήματα 400G DR4, FR4 και 800G χρησιμοποιούνται συνήθως σε αυτά τα σενάρια.
Οι συνδέσεις μεταξύ διακομιστή φύλλου και GPU είναι συχνά μικρότερες και ενδέχεται να χρησιμοποιούν:
Καλώδια DAC για μικρές αποστάσεις
AOCs για μεσαία εμβέλεια
Οπτικά συστήματα πολλαπλών λειτουργιών SR για ευέλικτες διατάξεις rack
Η σωστή επιλογή εξαρτάται από την πυκνότητα του rack και τον θερμικό σχεδιασμό.
|
Τεχνολογία |
Πλεονεκτήματα |
Περιορισμοί |
Τυπική περίπτωση χρήσης |
|---|---|---|---|
|
Οπτικές ίνες |
Μεγάλη εμβέλεια, υψηλό εύρος ζώνης, επεκτασιμότητα |
Υψηλότερο κόστος |
Υφάσματα με φύλλα ράχης |
|
DAC |
Χαμηλό κόστος, χαμηλή ισχύς |
Πολύ μικρή απόσταση |
Συνδέσεις ίδιου rack |
|
AOC |
Ελαφρύ, εύκαμπτο, με μεγαλύτερη εμβέλεια από το DAC |
Υψηλότερο κόστος από το DAC |
Σύνδεσμοι GPU μεταξύ rack |
Στη σύγχρονη δικτύωση συμπλεγμάτων τεχνητής νοημοσύνης, οι περισσότερες μεγάλης κλίμακας αναπτύξεις συνδυάζουν οπτικές ίνες, DAC και AOC για να εξισορροπήσουν το κόστος, την πυκνότητα, την ενεργειακή απόδοση και την επεκτασιμότητα.
Ο σχεδιασμός εύρους ζώνης είναι ένα κρίσιμο μέρος του σχεδιασμού δικτύωσης συμπλεγμάτων τεχνητής νοημοσύνης. Το ανεπαρκές εύρος ζώνης δικτύου μπορεί να μειώσει την αξιοποίηση της GPU, να αυξήσει τον χρόνο εκπαίδευσης και να δημιουργήσει σημεία συμφόρησης σε όλο το πλέγμα. Η σωστή χωρητικότητα δικτύου εξαρτάται σε μεγάλο βαθμό από τον τύπο φόρτου εργασίας, το μέγεθος του συμπλέγματος και τις μελλοντικές απαιτήσεις κλιμάκωσης.
Διαφορετικά φόρτα εργασίας τεχνητής νοημοσύνης δημιουργούν πολύ διαφορετικά μοτίβα κυκλοφορίας.
Η κατανεμημένη εκπαίδευση τεχνητής νοημοσύνης δημιουργεί εξαιρετικά υψηλή κίνηση ανατολικά-δυτικά, επειδή οι GPU ανταλλάσσουν συνεχώς κλίσεις, τενσόρους και παραμέτρους μοντέλου κατά τη διάρκεια των λειτουργιών συγχρονισμού.
Τα εκπαιδευτικά περιβάλλοντα συνήθως απαιτούν:
Εξαιρετικά υψηλή απόδοση
Χαμηλό latency
Επικοινωνία με δυνατότητα RDMA
Χαμηλά ποσοστά υπερεγγραφής
Τα clusters εκπαίδευσης μεγάλων γλωσσικών μοντέλων (LLM) συχνά βασίζονται σε fabrics 400G ή 800G για να διατηρούν αποτελεσματικό συγχρονισμό GPU.
Τα φόρτα εργασίας συμπερασμάτων συνήθως απαιτούν λιγότερο εύρος ζώνης επειδή η επικοινωνία μεταξύ των κόμβων είναι χαμηλότερη.
Τα δίκτυα συμπερασμάτων συχνά δίνουν προτεραιότητα σε:
Γρήγορος χρόνος απόκρισης
Αίτημα επεκτασιμότητας
Αποδοτικότητα κόστους
Ευέλικτη ανάπτυξη
Σε πολλά περιβάλλοντα συμπερασμάτων, τα υφάσματα Ethernet 100G ή 400G είναι επαρκή ανάλογα με το μέγεθος του μοντέλου και τον όγκο κίνησης.
Οι απαιτήσεις εύρους ζώνης αυξάνονται σημαντικά καθώς τα φόρτα εργασίας τεχνητής νοημοσύνης κλιμακώνονται σε πολλαπλούς διακομιστές.
Οι διακομιστές GPU ενός κόμβου βασίζονται κυρίως σε εσωτερικές διασυνδέσεις GPU όπως NVLink ή PCIe, μειώνοντας την εξάρτηση από εξωτερικά δίκτυα.
Αυτά τα περιβάλλοντα συνήθως απαιτούν μικρότερο εύρος ζώνης fabric.
Οι αναπτύξεις πολλαπλών κόμβων δημιουργούν πολύ μεγαλύτερη δικτυακή κίνηση, επειδή οι GPU πρέπει να συγχρονίζουν συνεχώς τα δεδομένα σε όλους τους διακομιστές.
Καθώς το μέγεθος του cluster μεγαλώνει:
Η κυκλοφορία από την Ανατολή προς τη Δύση αυξάνεται ραγδαία
Ο κίνδυνος συμφόρησης αυξάνεται
Τα υφάσματα χαμηλής καθυστέρησης γίνονται πιο σημαντικά
Αυξάνεται η ζήτηση για οπτικές διασυνδέσεις
Τα μεγάλα κατανεμημένα συμπλέγματα εκπαίδευσης συχνά απαιτούν μη μπλοκαρισμένες αρχιτεκτονικές spine-leaf 400G ή 800G.
Οι απαιτήσεις για υποδομές τεχνητής νοημοσύνης εξελίσσονται ραγδαία. Πολλοί οργανισμοί που αρχικά ανέπτυσσαν δίκτυα 100G αναβαθμίζουν τώρα σε δίκτυα 400G και προετοιμάζονται για επεκτασιμότητα 800G.
Κατά τον σχεδιασμό υφασμάτων τεχνητής νοημοσύνης, είναι σημαντικό να λάβετε υπόψη:
Μελλοντική επέκταση GPU
Αύξηση μεγεθών μοντέλων
Υψηλότερη πυκνότητα ραφιών
Διαδρομές αναβάθμισης οπτικών μονάδων
Ισχύς διακόπτη και ικανότητα ψύξης
Ο σχεδιασμός με γνώμονα τη μελλοντική επεκτασιμότητα μπορεί να μειώσει τους δαπανηρούς επανασχεδιασμούς δικτύων αργότερα.
Παρόλο που οι απαιτήσεις ποικίλλουν ανάλογα με το φόρτο εργασίας, αρκετές πρακτικές οδηγίες χρησιμοποιούνται συνήθως στη σύγχρονη δικτύωση Τεχνητής Νοημοσύνης.
Κατάλληλο για:
Μικρά συμπλέγματα GPU
Περιβάλλοντα συμπερασμάτων
Συστήματα ανάπτυξης και δοκιμών
Συνιστάται για:
Μεσαίες έως μεγάλες ομάδες εκπαίδευσης Τεχνητής Νοημοσύνης
Αναπτύξεις GPU πολλαπλών ραφιών
Υφάσματα RoCEv2 υψηλής απόδοσης
Σύγχρονες αρχιτεκτονικές με ράχη
Το 400G έχει γίνει η κύρια επιλογή για πολλά κέντρα δεδομένων τεχνητής νοημοσύνης για επιχειρήσεις.
Ταιριάζει καλύτερα για:
Υπερκλιμακωτή υποδομή τεχνητής νοημοσύνης
Εξαιρετικά μεγάλη κατανεμημένη εκπαίδευση
Μελλοντικά ανθεκτικά υφάσματα GPU
Πλατφόρμες μεταγωγής τεχνητής νοημοσύνης υψηλής πυκνότητας
Τα υφάσματα 800G συμβάλλουν στη βελτίωση της επεκτασιμότητας, της πυκνότητας θυρών και της μακροπρόθεσμης αποδοτικότητας εύρους ζώνης, καθώς τα φόρτα εργασίας τεχνητής νοημοσύνης συνεχίζουν να επεκτείνονται.
Ακόμα και τα καλά σχεδιασμένα clusters τεχνητής νοημοσύνης (AI) μπορούν να αντιμετωπίσουν προβλήματα δικτύωσης που μειώνουν την αξιοποίηση της GPU και επιβραδύνουν την κατανεμημένη εκπαίδευση. Επειδή τα φόρτα εργασίας τεχνητής νοημοσύνης είναι ιδιαίτερα ευαίσθητα στην καθυστέρηση και τη συμφόρηση, μικρά προβλήματα δικτύου μπορούν να επηρεάσουν γρήγορα τη συνολική απόδοση του cluster.

Παρακάτω παρατίθενται μερικά από τα πιο συνηθισμένα προβλήματα δικτύωσης συμπλεγμάτων τεχνητής νοημοσύνης και οι πρακτικές λύσεις τους.
Οι απροσδόκητες αυξήσεις στην καθυστέρηση μπορούν να διακόψουν τον συγχρονισμό της GPU και να επιβραδύνουν τις συλλογικές λειτουργίες επικοινωνίας, όπως το All-Reduce.
Οι συνήθεις αιτίες περιλαμβάνουν:
Υπερσυνδρομή δικτύου
Συμφορημένοι σύνδεσμοι σπονδυλικής στήλης
Ακατάλληλες πολιτικές QoS
Υψηλό φορτίο διακοπής CPU
Άνιση κατανομή κυκλοφορίας
Για να μειώσετε τις αιχμές καθυστέρησης:
Χρησιμοποιήστε υφάσματα χωρίς αποκλεισμό ή με χαμηλή υπερσυνδρομή
Ενεργοποιήστε το RDMA όπου είναι δυνατόν
Βελτιστοποίηση εξισορρόπησης φορτίου ECMP
Βελτιώστε την ευθυγράμμιση συγγένειας GPU και NUMA
Παρακολούθηση χρήσης buffer διακόπτη
Η σταθερή χαμηλή καθυστέρηση είναι κρίσιμη για τη διατήρηση αποτελεσματικής κατανεμημένης εκπαίδευσης τεχνητής νοημοσύνης.
Η απώλεια πακέτων είναι ιδιαίτερα επιβλαβής σε περιβάλλοντα εκπαίδευσης τεχνητής νοημοσύνης, επειδή οι αναμεταδόσεις μπορούν να καθυστερήσουν τον συγχρονισμό σε χιλιάδες GPU.
Η συμφόρηση συχνά προκαλείται από:
Έντονη κυκλοφορία από ανατολικά προς δυτικά
Ανεπαρκές εύρος ζώνης ανοδικής ζεύξης
Κακή διαχείριση ουράς
Διακοπή κυκλοφορίας κατά τη διάρκεια συλλογικών επιχειρήσεων
Οι κοινές λύσεις περιλαμβάνουν:
Ανάπτυξη τεχνολογιών Ethernet χωρίς απώλειες
Σωστή ρύθμιση παραμέτρων PFC και ECN
Αύξηση του εύρους ζώνης του fabric
Μείωση των ποσοστών υπερεγγραφής
Χρήση έξυπνων μηχανισμών ελέγχου συμφόρησης
Τα fabrics InfiniBand συνήθως παρέχουν ενσωματωμένη διαχείριση συμφόρησης, ενώ τα περιβάλλοντα RoCEv2 απαιτούν πιο προσεκτική ρύθμιση.
Η ακατάλληλη διαμόρφωση RDMA είναι μία από τις πιο συνηθισμένες αιτίες ασταθούς απόδοσης δικτύου AI.
Τυπικά προβλήματα περιλαμβάνουν:
Λανθασμένες ρυθμίσεις MTU
Λανθασμένη διαμόρφωση PFC
Ακατάλληλη διαμόρφωση DCB
Ανισορροπία ουράς RDMA
Μη συμβατές ρυθμίσεις διακόπτη
Τα συμπτώματα μπορεί να περιλαμβάνουν:
Αστάθεια επικοινωνίας GPU
Χαμηλή απόδοση NCCL
Μη αναμενόμενες ρίψεις πακέτων
Υψηλή καθυστέρηση κατά την κατανεμημένη εκπαίδευση
Για να βελτιώσετε τη σταθερότητα του RDMA:
Τυποποίηση διαμόρφωσης δικτύου σε όλο το σύμπλεγμα
Επικύρωση συμπεριφοράς PFC και ECN
Χρησιμοποιήστε συνεπείς ρυθμίσεις MTU
Ελέγξτε την απόδοση του RDMA τακτικά
Παρακολούθηση της αποτελεσματικότητας της επικοινωνίας του NCCL
Τα συμπλέγματα τεχνητής νοημοσύνης εξαρτώνται σε μεγάλο βαθμό από τη συμβατότητα μεταξύ των καρτών δικτύου (NIC), των διακοπτών (switches), των GPU και των λειτουργικών συστημάτων. Οι αναντιστοιχίες υλικολογισμικού μπορούν να δημιουργήσουν απρόβλεπτα προβλήματα απόδοσης ή αποτυχίες RDMA.
Συνήθεις προβληματικοί τομείς περιλαμβάνουν:
Ασυνέπειες υλικολογισμικού κάρτας δικτύου (NIC)
Ασυμβατότητα λογισμικού διακόπτη
Αναντιστοιχίες προγραμμάτων οδήγησης GPU
Μη υποστηριζόμενες εκδόσεις δυνατοτήτων RDMA
Οι βέλτιστες πρακτικές περιλαμβάνουν:
Διατήρηση τυποποιημένων εκδόσεων υλικολογισμικού σε ολόκληρο το σύμπλεγμα
Επικύρωση συμβατότητας πριν από τις αναβαθμίσεις
Διατήρηση τεκμηριωμένων βασικών γραμμών λογισμικού
Δοκιμή ενημερώσεων πρώτα σε περιβάλλοντα προετοιμασίας
Η συνεπής διαχείριση υλικολογισμικού είναι απαραίτητη για σταθερές λειτουργίες τεχνητής νοημοσύνης μεγάλης κλίμακας.
Ορισμένα clusters τεχνητής νοημοσύνης αντιμετωπίζουν άνιση χρήση εύρους ζώνης, όπου ορισμένοι σύνδεσμοι παρουσιάζουν συμφόρηση, ενώ άλλοι παραμένουν υποαξιοποιημένοι.
Αυτό συχνά προκαλείται από:
Αναποτελεσματικός κατακερματισμός ECMP
Κακή σχεδίαση τοπολογίας
Σημεία κυκλοφορίας
Μη ισορροπημένες διαδρομές επικοινωνίας GPU
Για να βελτιώσετε την αξιοποίηση του υφάσματος:
Βελτιστοποίηση σχεδιασμού τοπολογίας spine-leaf
Ρύθμιση πολιτικών ECMP
Ισορροπία διαδρομών κυκλοφορίας μεταξύ των διακοπτών
Παρακολουθήστε συνεχώς την κατανομή της ροής
Χρησιμοποιήστε εργαλεία τηλεμετρίας και ανάλυσης υφασμάτων
Η αποτελεσματική αξιοποίηση των συνδέσμων βοηθά στη μεγιστοποίηση του διαθέσιμου εύρους ζώνης και στη βελτίωση της συνολικής επεκτασιμότητας της εκπαίδευσης τεχνητής νοημοσύνης.

Το καλύτερο δίκτυο για ένα σύμπλεγμα τεχνητής νοημοσύνης εξαρτάται από την κλίμακα του φόρτου εργασίας, τις απαιτήσεις καθυστέρησης και τον προϋπολογισμό. Τα μεγάλης κλίμακας κατανεμημένα περιβάλλοντα εκπαίδευσης τεχνητής νοημοσύνης χρησιμοποιούν συχνά το InfiniBand λόγω της εξαιρετικά χαμηλής καθυστέρησης και της ισχυρής απόδοσης RDMA. Οι εταιρικές αναπτύξεις τεχνητής νοημοσύνης επιλέγουν συνήθως το RoCEv2 έναντι του Ethernet για ισορροπία μεταξύ επεκτασιμότητας, κόστους και λειτουργικής ευελιξίας.
Το InfiniBand γενικά προσφέρει χαμηλότερη καθυστέρηση και πιο ώριμη διαχείριση συμφόρησης για υπερκλιμακωτά clusters εκπαίδευσης τεχνητής νοημοσύνης. Ωστόσο, το RoCEv2 έχει γίνει μια δημοφιλής εναλλακτική λύση επειδή συνδυάζει την απόδοση RDMA με την τυπική υποδομή Ethernet, μειώνοντας το κόστος ανάπτυξης και βελτιώνοντας τη συμβατότητα με τα εταιρικά δίκτυα.
Για πολλούς οργανισμούς, το RoCEv2 προσφέρει την καλύτερη ισορροπία μεταξύ απόδοσης και επεκτασιμότητας.
Τα σύγχρονα clusters εκπαίδευσης τεχνητής νοημοσύνης βασίζονται ολοένα και περισσότερο σε οπτικές μονάδες 400G και 800G για την υποστήριξη επικοινωνίας GPU υψηλού εύρους ζώνης.
Τα οπτικά συστήματα 400G είναι πλέον συνηθισμένα σε μεσαίες έως μεγάλες εφαρμογές τεχνητής νοημοσύνης.
Τα οπτικά συστήματα 800G χρησιμοποιούνται κυρίως σε υφάσματα υπερκλίμακας και τεχνητής νοημοσύνης επόμενης γενιάς.
Μικρότερα συμπλέγματα συμπερασμάτων και περιβάλλοντα ανάπτυξης ενδέχεται να εξακολουθούν να λειτουργούν αποτελεσματικά με δικτύωση 100G.
Ναι. Τα σύγχρονα δίκτυα Ethernet σε συνδυασμό με τις τεχνολογίες RoCEv2 και RDMA μπορούν να υποστηρίξουν αποτελεσματικά την εκπαίδευση τεχνητής νοημοσύνης μεγάλης κλίμακας. Πολλά κέντρα δεδομένων τεχνητής νοημοσύνης για επιχειρήσεις χρησιμοποιούν πλέον Ethernet υψηλής ταχύτητας με διαμορφώσεις δικτύου χωρίς απώλειες για κατανεμημένα φόρτα εργασίας GPU.
Ωστόσο, τα δίκτυα τεχνητής νοημοσύνης που βασίζονται στο Ethernet απαιτούν προσεκτική ρύθμιση τεχνολογιών όπως:
PFC (Έλεγχος Ροής με Προτεραιότητα)
ECN (Ρητή Ειδοποίηση Συμφόρησης)
DCB (Γεφύρωση Κέντρων Δεδομένων)
Χωρίς σωστή διαμόρφωση, η συμφόρηση και η απώλεια πακέτων μπορούν να μειώσουν την αποτελεσματικότητα της εκπαίδευσης.
Οι οπτικές μονάδες επηρεάζουν άμεσα το εύρος ζώνης, την καθυστέρηση, την επεκτασιμότητα και την αξιοπιστία του σήματος σε δίκτυα συμπλεγμάτων τεχνητής νοημοσύνης.
Οι πομποδέκτες υψηλής ταχύτητας, όπως οι μονάδες QSFP-DD και OSFP, επιτρέπουν:
Συνδεσιμότητα 400G και 800G
Επικοινωνία μεταξύ σπονδυλικής στήλης και φύλλων σε μεγάλες αποστάσεις
Υφάσματα GPU υψηλής πυκνότητας
Χαμηλότερη υποβάθμιση σήματος
Καλύτερη επεκτασιμότητα για κατανεμημένα φόρτα εργασίας τεχνητής νοημοσύνης
Η επιλογή των σωστών οπτικών για συνδέσεις switch-to-switch και switch-to-server βοηθά στη βελτίωση της συνολικής απόδοσης του συμπλέγματος AI και της μελλοντικής επεκτασιμότητας.
Καθώς η υποδομή τεχνητής νοημοσύνης συνεχίζει να κινείται προς μεγαλύτερα clusters GPU και fabrics 400G/800G, οι αποφάσεις σχεδιασμού δικτύου που λαμβάνονται σήμερα θα επηρεάσουν άμεσα τη μακροπρόθεσμη επεκτασιμότητα, τη λειτουργική σταθερότητα και το κόστος ανάπτυξης. Τα επιτυχημένα έργα δικτύωσης clusters τεχνητής νοημοσύνης δεν επικεντρώνονται πλέον μόνο στο ακατέργαστο εύρος ζώνης — δίνουν επίσης προτεραιότητα στην παρατηρησιμότητα, τη διαλειτουργικότητα και τη μελλοντική οπτική επεκτασιμότητα.

Οι συστάδες τεχνητής νοημοσύνης δημιουργούν τεράστιες ποσότητες κυκλοφορίας από ανατολή προς δύση, καθιστώντας την ορατότητα και την παρακολούθηση απαραίτητη. Οι σύγχρονοι ιστοί τεχνητής νοημοσύνης θα πρέπει να περιλαμβάνουν:
Τηλεμετρία σε πραγματικό χρόνο
Παρακολούθηση συμφόρησης
Ανάλυση απόδοσης RDMA
Ορατότητα επικοινωνίας GPU
Διαγνωστικά με διακόπτη και οπτικά
Η έγκαιρη παρατηρησιμότητα βοηθά στον εντοπισμό σημείων συμφόρησης προτού αυτά επηρεάσουν την αξιοποίηση της GPU και την αποτελεσματικότητα της εκπαίδευσης.
Η δέσμευση σε προμηθευτές μπορεί να περιορίσει τη μελλοντική επεκτασιμότητα και να αυξήσει το κόστος υποδομής. Όποτε είναι δυνατόν, οι οργανισμοί θα πρέπει να σχεδιάζουν υφάσματα τεχνητής νοημοσύνης γύρω από ανοιχτά πρότυπα Ethernet, διαλειτουργικά οπτικά και ευέλικτες αρχιτεκτονικές spine-leaf.
Μια στρατηγική ουδέτερη ως προς τον προμηθευτή βελτιώνει:
Ευελιξία υλικού
Επιλογές αναβάθμισης
Μακροπρόθεσμος έλεγχος κόστους
Συμβατότητα πολλαπλών προμηθευτών
Οι ασυνέπειες στο υλικολογισμικό είναι μία από τις πιο συνηθισμένες αιτίες αστάθειας δικτύου τεχνητής νοημοσύνης. Η τυποποίηση του υλικολογισμικού της κάρτας δικτύου (NIC), του λογισμικού του διακόπτη, των οπτικών μονάδων και των τύπων καλωδίων βοηθά στη μείωση των απροσδόκητων προβλημάτων διαλειτουργικότητας.
Οι βέλτιστες πρακτικές περιλαμβάνουν:
Διατήρηση συνεπών εκδόσεων υλικολογισμικού
Χρήση επικυρωμένων λιστών οπτικής συμβατότητας
Τυποποίηση της ανάπτυξης DAC, AOC και οπτικών ινών
Δοκιμή αναβαθμίσεων πριν από την κυκλοφορία στην παραγωγή
Τα μεγάλα fabric τεχνητής νοημοσύνης μπορούν να γίνουν εξαιρετικά περίπλοκα. Η σωστή τεκμηρίωση απλοποιεί την αντιμετώπιση προβλημάτων και τη μελλοντική επέκταση.
Σημαντικά στοιχεία προς τεκμηρίωση περιλαμβάνουν:
Σχεδιασμός τοπολογίας φύλλου ράχης
Ρυθμίσεις RDMA και RoCE
Πολιτικές ECMP
Αναλογίες υπερεγγραφής
Σχέδια ανάπτυξης οπτικών μονάδων
Παράμετροι συντονισμού NCCL
Τα καλά τεκμηριωμένα περιβάλλοντα είναι πιο εύκολο να κλιμακωθούν και να συντηρηθούν με την πάροδο του χρόνου.
Η μελλοντική ανάπτυξη της τεχνητής νοημοσύνης θα απαιτήσει πολύ περισσότερα από πρόσθετες θύρες μεταγωγής. Η πυκνότητα οπτικού εύρους ζώνης, η ενεργειακή απόδοση και η διαχείριση καλωδίων καθίστανται εξίσου σημαντικοί παράγοντες σχεδιασμού.
Οι οργανισμοί που αναπτύσσουν νέες υποδομές τεχνητής νοημοσύνης θα πρέπει ήδη να προετοιμάζονται για:
Διαδρομές μετανάστευσης από 400G σε 800G
Υψηλότερη πυκνότητα ραφιών
Υιοθέτηση OSFP και QSFP-DD800
Κλιμακούμενη υποδομή οπτικών ινών
Μελλοντικές αρχιτεκτονικές υπερ-συστάδων
Η έγκαιρη επιλογή του σωστού οπτικού οικοσυστήματος μπορεί να μειώσει σημαντικά την πολυπλοκότητα μελλοντικής αναβάθμισης.
Καθώς η δικτύωση συμπλεγμάτων τεχνητής νοημοσύνης συνεχίζει να εξελίσσεται, οι οπτικές διασυνδέσεις υψηλής ποιότητας και τα αξιόπιστα στοιχεία Ethernet θα παραμείνουν θεμελιώδη για την κλιμακούμενη υποδομή GPU. Για τους οργανισμούς που σχεδιάζουν σύγχρονα υφάσματα τεχνητής νοημοσύνης, το LINK-PP Επίσημο κατάστημα παρέχει ένα ευρύ φάσμα οπτικών μονάδων υψηλής ταχύτητας, λύσεων DAC/AOC και προϊόντων συνδεσιμότητας δικτύωσης σχεδιασμένων για εταιρικές αναπτύξεις Τεχνητής Νοημοσύνης, HPC και κέντρων δεδομένων.

Συνδεθείτε ή δημιουργήστε έναν λογαριασμό για να παρακολουθείτε το αίτημά σας στο διαδίκτυο.